SAP BW - Quick Guide
SAP BW - Overview of SAP BI
In this chapter, we will get to understand the basics of SAP BW and SAP BI. How it has evolved and improved over the years.
SAP BW and BI Introduction
SAP Business Intelligence (BI) means analyzing and reporting of data from different heterogeneous data sources. SAP Business Warehouse (BW) integrates data from different sources, transforms and consolidates the data, does data cleansing, and storing of data as well. It also includes data modeling, administration and staging area.
The data in SAP BW is managed with the help of a centralized tool known as SAP BI Administration Workbench. The BI platform provides infrastructure and functions which include −
- OLAP Processor
- Metadata Repository,
- Process designer and other functions.
The Business Explorer (BEx) is a reporting and analysis tool that supports query, analysis and reporting functions in BI. Using BEx, you can analyze historical and current data to different degree of analysis.
SAP BW is known as an open, standard tool which allows you to extract the data from different systems and then send it to the BI system. It also evaluates the data with different reporting tools and you can distribute this to other systems.
The following diagram shows an open, broad and standard based Architecture of Business Intelligence.

- BI stands for Business Intelligence
- BW stands for Business Warehouse
In 1997, SAP had first introduced a product for reporting, analysis and data warehousing and it was named as Business Warehouse Information System (BIW).
Later, the name was changed from SAP BIW to SAP Business Warehouse (BW). After SAP acquired Business Objects, the name of the product has been changed to SAP BI.
| Name |
BIW Version |
Release Date and Year |
| BIW |
1.2A |
Oct 1998 |
| BIW |
1.2B |
Sep 1999 |
| BIW |
2.0A |
Feb 2000 |
| BIW |
2.0B |
Jun 2000 |
| BIW |
2.1C |
Nov 2000 |
| BW (Name changed to BW) |
3.0A |
Oct 2001 |
| BW |
3.0B |
May 2002 |
| BW |
3.1 |
Nov 2002 |
| BW |
3.1C |
Apr 2004 |
| BW |
3.3 |
Apr 2004 |
| BW |
3.5 |
Apr 2004 |
| BI (Name changed to BI) |
7 |
Jul 2005 |
Data Acquisition in SAP BI
SAP BI allows you to acquire data from multiple data sources that can be distributed to different BI systems. A SAP Business Intelligence system can work as a target system for data transfer or source system for distribution of data to different BI targets.

As mentioned in the above image, you can see SAP BI source systems along with other systems −
- SAP systems (SAP Applications/SAP ECC)
- Relational Database (Oracle, SQL Server, etc.)
- Flat File (Excel, Notepad)
- Multidimensional Source systems (Universe using UDI connector)
- Web Services that transfer data to BI by means of push
When you go to SAP BI Administration workbench, the source system is defined there. Go to RSA1 → Source Systems


As per the data source type, you can differentiate between the source systems −
- Data Sources for transaction data
- Data Sources for master data
- Data Sources for hierarchies
- Data Sources for text
- Data Sources for attributes
You can load the data from any source in the data source structure into BI with an InfoPackage. Target system where the data is to be loaded is defined in the transformation.
InfoPackage
An InfoPackage is used to specify how and when to load data to the BI system from different data sources. An InfoPackage contains all the information on how the data is loaded from the source system to a data source or a PSA. InfoPackage consists of condition for requesting data from a source system.
Note − Using an InfoPackage in BW 3.5, you can load data in Persistence Staging Area and also in targets from source system, but If you are using SAP BI 7.0 the data load should be restricted to PSA only for latest versions.
BI Data Flow (InfoPackage and InfoProvider)

BI Content
BI objects consists of the following components −
- Roles
- Web templates and workbook
- Queries
- InfoProvider
- Update Rules
- InfoSource
- Transfer Rules
- InfoObjects
- DataSources
BI objects are divided into multiple BI content areas so that they can be used in an efficient way. This includes content area from all the key modules in an organization, which include −
- SCM
- CRM
- HR
- Finance Management
- Product Lifecycle
- Industry Solutions
- Non-SAP data sources, etc.
SAP BW - Data Warehousing
In this chapter, we will discuss about Star and Extended Star Schema. We will also understand what InfoArea and InfoObjects are.
Star Schema
In Star Schema, each dimension is joined to one single fact table. Each dimension is represented by only one dimension and it is not further normalized. A dimension Table contains a set of attributes that are used to analyze the data.
For example − We have a fact table called FactSales that has primary keys for all the Dim tables and measures units_sold and dollars_sold to do analysis.
We have 4 Dimension tables − DimTime, DimItem, DimBranch, DimLocation as shown in the following image.

Each dimension table is connected to a fact table as the fact table has the primary Key for each dimension tables that are used to join two tables.
Facts/Measures in the Fact Table are used for analysis purpose along with the attribute in the dimension tables.
Extended Star Schema
In Extended Star schema, fact tables are connected to dimension tables and this dimension table is further connected to SID table and this SID table is connected to master data tables. In an extended star schema, you have the fact and dimension tables inside the cube, however SID tables are outside the cube. When you load the transactional data into the Info cube, the Dim Id’s are generated based on SID’s and these Dim ids’ are then used in the fact tables.
In the extended star schema one fact table can connect to 16 dimension tables and each dimension table is assigned with 248 maximum SID tables. These SID tables are also called as characteristics and each characteristic can have master data tables like ATTR, Text, etc.

InfoArea and InfoObjects
InfoObjects are known as the smallest unit in SAP BI and are used in Info Providers, DSO’s, Multi providers, etc. Each Info Provider contains multiple InfoObjects.
InfoObjects are used in reports to analyze the data stored and to provide information to decision makers. InfoObjects can be categorized into the following categories −
- Characteristics like Customer, Product, etc.
- Units like Quantity sold, currency, etc.
- Key Figures like Total Revenue, Profit, etc.
- Time characteristics like Year, quarter, etc.
InfoObjects are created in InfoObject catalog. It is possible that an InfoObject can be assigned to a different Info Catalog.
Info Area
Info Area in SAP BI is used to group similar types of objects together. Info Area is used to manage Info Cubes and InfoObjects. Each InfoObjects resides in an Info Area and you can define it in a folder which is used to hold similar files together.

SAP BW - Data Flow
In this chapter, we will discuss about data flow and data acquisition in SAP BW.
Overview of Data Flow
Data flow in data acquisition involves transformation, info package for loading to PSA, and data transfer process for distribution of data within BI. In SAP BI, you determine which data source fields are required for decision making and should be transferred.
When you activate the data source, a PSA table is generated in SAP BW and then data can be loaded.
In the transformation process, fields are determined for InfoObjects and their values. This is done by using the DTP data which is transferred from PSA to different target objects.
The transformation process involves the following different steps −
- Data Consolidation
- Data Cleansing
- Data Integration

When you move the data from one BI object to another BI object, the data is using a transformation. This transformation converts the source field in to the format of the target. Transformation is created between a source and a target system.
BI Objects − InfoSource, DataStore objects, InfoCube, InfoObjects, and InfoSet act as the source objects and these same objects serve as target objects.
A Transformation should consist of at least one transformation rule. You can use different transformation, rule types from the list of available rules and you can create simple to complex transformations.
Directly Accessing Source System Data
This allows you to access data in the BI source system directly. You can directly access the source system data in BI without extraction using Virtual Providers. These Virtual providers can be defined as InfoProviders where transactional data is not stored in the object. Virtual providers allow only read access on BI data.
There are different types of Virtual Providers that are available and can be used in various scenarios −
- VirtualProviders based on DTP
- VirtualProviders with function modules
- VirtualProviders based on BAPI’s
VirtualProviders Based on DTP
These VirtualProviders are based on the data source or an InfoProvider and they take characteristics and key figures of the source. Same extractors are used to select data in a source system as you use to replicate data into the BI system.
- When are Virtual Providers based on DTP?
- When only some amount of data is used.
- You need to access up to date data from a SAP source system.
- Only few users execute queries simultaneously on the database.
Virtual Providers based on DTP shouldn’t be used in the following conditions −
When multiple users are executing queries together.
When same data is accessed multiple times.
When a large amount of data is requested and no aggregations are available in the source system.
Creating a VirtualProvider based on DTP
To go to Administration Workbench, use RSA1

In the Modeling tab → go to Info Provider tree → In Context menu → Create Virtual Provider.

In Type Select Virtual Provider based on Data Transfer Process for direct access. You can also link a Virtual Provider to a SAP source using an InfoSource 3.x.

A Unique Source System Assignment Indicator is used to control the source system assignment. If you select this indicator, only one source system can be used in the assignment dialog. If this indicator is not checked, you can select more than one source system and a Virtual Provider can be considered as a multi-provider.

Click on Create (F5) at the bottom. You can define the virtual provider by copying objects. To Activate the Virtual Provider, click as shown in the following screenshot.

To define Transformation, right click and go to Create Transformation.

Define the Transformation rules and activate them.

The next step is to create a Data Transfer Process. Right click → Create Data Transfer Process

The default type of DTP is DTP for Direct access. You have to select the source for Virtual Provider and activate DTP.
To activate direct access, context menu → Activate Direct Access.

Select one or more Data transfer processes and activate the assignment.

Virtual Providers with BAPIs
This is used for reporting on the data in external systems and you don’t need to store transaction data in the BI system. You can connect to non-SAP systems like hierarchical databases.
When this Virtual Provider is used for reporting, it calls Virtual Provider BAPI.
Virtual Provider with Function Module
This Virtual Provider is used to display data from a non BI data source to a BI without copying the data to BI structure. The data can be local or remote. This is primarily used for SEM applications.
If you compare this with other Virtual Providers, this is more generic and offer more flexibility, however you need to put a lot of efforts in implementing this.
Enter the name of the Function Module that you want to use as data source for Virtual Providers.

SAP BW - Transformation
The Transformation process is used to perform data consolidation, cleansing and data integration. When data is loaded from one BI object to other BI object, transformation is applied on the data. Transformation is used to convert a field of source into the target object format.
Each Transformation consists of minimum one transformation rule. As different rule types and routines are available that allows you to create simple to complex transformations.

To create Transformation, go to context and right click → Create Transformation.

In the next window, you will be prompted to enter the Source of Transformation and Name and the click on tick mark box.

A rule is created from source to target system and mapping is displayed.

Transformation Rules
Transformation rules are used to map source fields and target fields. Different rule types can be used for transformation.
Rule Type − A rule type is defined as an operation applied on the fields using a Transformation rule.
Rule Group − It is defined as the group of transformation rules and each key field in the target contains one transformation rule.
Transformation Type − It is used to determine the transformation values and how data is entered in the target.
Routines − Routines are used to perform complex transformations. Routines are defined as local ABAP classes and it consists of predefined definition and implementation area.
A Routine is created in implementation area and inbound and outbound parameters are defined in definition area. Routines can be defined as transformation rule for a key figure and they are available as rule types.
Real-Time Data Acquisition (RDA)
Real-time data acquisition is based on moving data to Business Warehouse in real time. Data is sent to delta queue or PSA table in real time. The real time data acquisition is used when you transfer data more frequently – hourly or every minute and data is refreshed at the report level multiple times in a single time interval.
Real-time data acquisition is one of the key properties of data source and data source should support real time data acquisition. Data Source which are configured to transfer data in real time they can’t be used for standard data transfer.
Real time data acquisition can be achieved in two scenarios −
Real-time Data Acquisition Background Process −
To process data to InfoPackage and data transfer process DTP at regular intervals, you can use a background process known as Daemon.
Daemon process gets all the information from InfoPackage and DTP that which data is to be transferred and which PSA and Data sore objects to be loaded with data.
SAP BW - InfoArea, Object and Catalog
In this chapter, we will discuss in detail about a few SAP BW components called as InfoArea, InfoObject, and Catalog.
InfoArea in SAP BI
InfoArea in SAP BI is used to group similar types of objects together. InfoArea is used to manage InfoCubes and InfoObjects. Each InfoObject resides in an InfoArea and you can define it in a folder which is used to hold similar files together.
How to create an Infoarea?
To create an Infoarea, go to RSA workbench. T-Code: RSA1

Go to Modeling tab → InfoProvider. Right click on Context → Create InfoArea.

Enter the name of InfoArea and description, click Continue.

InfoArea created will be shown at the bottom.

How to Create an InfoObject and InfoObject Catalog?
InfoObjects are known as the smallest unit in SAP BI and are used in InfoProviders, DSO’s, Multi providers, etc. Each InfoProvider contains multiple InfoObjects.
InfoObjects are used in reports to analyze the data stored and to provide information to the decision makers. InfoObjects can be categorized into the following categories −
- Characteristics like Customer, Product, etc.
- Units like Quantity sold, currency, etc.
- Key Figures like Total Revenue, Profit, etc.
- Time characteristics like Year, quarter, etc.
InfoObjects are created in the InfoObject Catalog. It is possible that an InfoObject can be assigned to a different Info Catalog.
Creating InfoObject Catalog
T-Code: RSA1
Go to Modeling → InfoObjects → Right Click → Create InfoObject Catalog.

Enter the Technical Name of the InfoObject Catalog and description.

Select InfoObject Type − Characteristic option button − This is a characteristic InfoObject Catalog.
Key Figure − This is the InfoObject Catalog that would be created.
Click on the create button. The next step is to save and activate the InfoObject Catalog. A new InfoObject Catalog is created as shown in the following screenshot −


Creating InfoObject
To create a InfoObject with characteristics, go to RSA1 and open administration Workbench. Go to Modeling → InfoObjects.
Select My Sales InfoObject Catalog → Right Click → Create InfoObjects.

Enter the Technical name of the characteristics and description. You can use the Reference Characteristics if the new characteristics, which have to be created has the same technical properties of an existing characteristic.
You can use template characteristics for a new characteristic that has some of the technical properties of an already existing characteristic. Click Continue.

In the next window you will get the Edit Screen of the InfoObject. The InfoObject Edit Screen has 6 following tabs which are also shown in the screenshot as well −
- General
- Business Explorer
- Master Data/Texts
- Hierarchy
- Attribute
- Compounding

Once all the fields are defined, click on save and activate.
Creating an InfoObject with Key Figures
To create an InfoObject with characteristics, go to RSA1 and open administration Workbench. Go to Modeling → InfoObjects

Go to Not Assigned Key Figures → Right Click → Create InfoObject.

Then you can −
- Enter the Technical name and description.
- Enter the Reference Key Figure
- Enter the Reference template and click on Continue.

In Edit characteristics, define the following fields −
- Type/Unit
- Aggregation
- Additional Properties
- Elimination

Click on save and Activate as shown in the following screenshot. This InfoObject will be saved and Active.
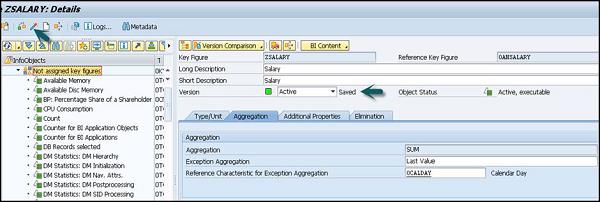
Editing an InfoObject
You can also change an existing InfoObject in Administration Workbench. Select InfoObject you want to maintain → Context menu → Change. You can also use maintain InfoObject icon from the toolbar menu.

This feature allows you to change only some properties of an InfoObject if it is used in the InfoProvider. You can change text and meaning of an InfoObject. The InfoObject with key figures – is not possible if the key figure type, data type or aggregation of the key figure is used in the InfoProvider.
You can use Check function for incompatible changes.
SAP BW - DataStore Objects & Types
In this chapter, we will discuss the various DataStore Objects and it sub-modules.
What is a DataStore Object?
A DSO (DataStore Object) is known as the storage place to keep cleansed and consolidated transaction or master data at the lowest granularity level and this data can be analyzed using the BEx query.
A DataStore Object contains key figures and the characteristic fields and data from a DSO can be updated using Delta update or other DataStore objects or even from the master data. These DataStore Objects are commonly stored in two dimensional transparent database tables.
DSO Architecture
The DSO component consists of the following three tables −
Activation Queue − This is used to store the data before it is activated. The key contains request id, package id and record number. Once the activation is done, the request is deleted from the activation queue.
Active Data Table − This table is used to store the current active data and this table contains the semantic key defined for data modeling.
Change Log − When you activate the object, changes done to the active data are re-stored in this change log. A change log is a PSA table and is maintained in Administration Workbench under the PSA tree.

When you load the new data in to a DSO and the technical key is added to records. A request is then added to the Activation queue. It can be triggered manually or automatically.
Types of DataStore Objects
You can define the DataStore Objects into the following types −
- Standard DSO
- Direct Update DSO
- Write-Optimized DSO
| Type |
Structure |
Data Supply |
SID Generation |
| Standard DataStore Object |
Consists of three tables: activation queue, table of active data, change log |
From data transfer process |
Yes |
| Write-Optimized Data Store Objects |
Consists of the table of Active data only |
From data transfer process |
No |
| DataStore Objects for Direct Update |
Consists of the table of Active data only |
From APIs |
No |
Standard DataStore Objects
To create a standard DSO, go to the RSA Workbench.
Use T-Code: RSA1

Go to Modeling tab → InfoProvider → Select InfoArea → Right click and click on create DataStore Object.

Enter the technical name and description of the DataStore object.
Type of DataStore Object → This is used to select the DSO type. It takes a standard DSO by default.
Click the Create (F5) button.

To change the DSO type, go to the settings tab as shown in the following screenshot. Click on the Edit icon and in a new window which opens, you can change the DataStore Object and also Select the Type.

SID Generation
SID is generated for each master data value. Click on Edit to change the settings for SID generation.

Create a SID
You can select from the following options −
- During Reporting
- During Activation or
- Never Create SIDs
Unique Data Records − This option is used to ensure the DSO holds unique values.
Set Quality Status to OK − This allows you to set the quality status after the data loading has been completed.

Key Fields and Data Fields − Key fields are used to add unique records. To add key filed, right click on Key fields and select InfoObject Direct Input.

In a new window, enter the technical names on the InfoObjects and click Continue. You can see that the InfoObject is added under the key fields section.

Following is the key filed InfoObject in the DSO. Once this DSO structure is complete, you can activate that DSO.


Direct Update DataStore Objects
DataStore Object for direct update allows you to access data for reporting and analysis immediately after it is loaded. It is different from standard DSOs owing to the way how it processes the data. This data is stored in the same format in which it was loaded in to the DataStore Object for any direct update by the application.
The Structure of Direct Update DSOs
These datastores contain one table for active data and no change log area exists. The data is retrieved from external systems using APIs.
The following API’s exist −
RSDRI_ODSO_INSERT − These are used to insert new data.
RSDRI_ODSO_INSERT_RFC − It is similar to RSDRI_ODSO_INSERT and can be called up remotely.
RSDRI_ODSO_MODIFY − This is used to insert data having new keys. For data with keys already in the system, the data is changed.
RSDRI_ODSO_MODIFY_RFC − This is similar to RSDRI_ODSO_MODIFY and can be called up remotely.
RSDRI_ODSO_UPDATE − This API is used to update the existing data.
RSDRI_ODSO_UPDATE_RFC − This is similar to RSDRI_ODSO_UPDATE and can be called up remotely.
RSDRI_ODSO_DELETE_RFC − This API is used to delete the data.
Benefits
In direct update DSO’s, the data is easily accessible. You can access data for reporting and analysis immediately after it is loaded.
Drawbacks
As the structure of this DSO contains one table for active data and no change log, so this doesn’t allow delta update to InfoProviders.
As the data loading process is not supported by BI system, so DSOs are not displayed in the administration section or in the monitor.
To create a direct update DataStore, go to administration workbench. Use T-Code: RSA1

Go to Modeling tab → InfoProvider → Select InfoArea → Right click and click on create DataStore Object.

Enter the technical name and description of the DataStore object.
Type of DataStore Object − This is used to select the DSO type. It takes a standard DSO by default.
Click on the Create (F5) button.

To change the DSO type, go to the settings tab as shown in the following screenshot. Click on the Edit icon and in a new window which opens, you can change the DataStore Object and also select its Type. Select the Direct Update DataStore and then click Continue.

Once the DataStore is defined, click on Activate button to activate DSO.

SAP BW - Write Optimized DSO
In the Write Optimized DSO, data that is loaded is available immediately for further processing.
Write Optimized DSO provides a temporary storage area for large sets of data if you are executing complex transformations for this data before it is written on to the DataStore object. The data can then be updated to further InfoProviders. You only have to create the complex transformations once for all data.
Write Optimized DSOs are used as the EDW layer for saving data. Business rules are only applied when the data is updated to additional InfoProviders.
In Write Optimized DSO, the system does not generate SIDs and you do not need to activate them. This means that you can save time and further process the data quickly. Reporting is possible on the basis of these DataStore objects.
Structure of Write Optimized DSO
It only contains the table of active data and there is no need to activate the data as required with the standard DSO. This allows you to process the data more quickly.
In Write optimized DSO, loaded data is not aggregated. If two data records with the same logical key are extracted from the source, both records are saved in the DataStore object. The record made responsible for aggregation remains, however, so that the aggregation of data can take place later in standard DataStore objects.
The system generates a unique technical key for the write-optimized DataStore object. The standard key fields are not necessary with this type of a DataStore object. If there are standard key fields anyway, they are called semantic keys, so that they can be distinguished from the other technical keys.
The technical keys consist of −
- Request GUID field (0REQUEST)
- Data Package field (0DATAPAKID)
- Data Record Number field (0RECORD) and you load only new data records.
Use T-Code: RSA1
Go to Modeling tab → InfoProvider → Select InfoArea → Right click and click on create DataStore Object.
Enter the technical name and description of the DataStore object.
Type of DataStore Object − This is used to select the DSO type. It takes a standard DSO by default.
Click on Create (F5) button as shown in the following screenshot.
To change the DSO type, go to the settings tab as shown in the following screenshot. Click on the Edit icon and when a new window opens, you can change the DataStore Object and also select the type which is required.

SAP BW - Infoset
In this chapter, we will discuss all about what an Infoset is, how to create and edit them, and what are its different types.
Infoset in SAP BI
Infosets are defined as a special type of InfoProviders where the data sources contain a join rule on the DataStore objects, standard InfoCubes or InfoObject with master data characteristics. Infosets are used to join data and that data is used in the BI system.
When an InfoObject contains time dependent characteristics, then that type of a join between data sources is called as a temporal join.
These temporal Joins are used to map a period of time. At the time of reporting, other InfoProviders handle time-dependent master data in such a way that the record that is valid for a pre-defined unique key date is used each time. You can define a Temporal join as a join that contains at least one time-dependent characteristic or a pseudo time-dependent InfoProvider.
An InfoSet can also be defined as a semantic layer over the data sources.
Uses of an Infoset
Infosets are used to analyze the data in multiple InfoProviders by combining master data characteristics, DataStore Objects, and InfoCubes.
You can use the temporal join with InfoSet to specify at a particular point of time when you want to evaluate the data.
You can use reporting using the Business Explorer BEx on DSO’s without enabling the BEx indicator.
Types of Infoset Joins
As Infoset is defined where data sources contain the join rule on DataStore objects, standard InfoCubes or InfoObject with the master data characteristics. The data joined using Infosets are available to use in BEx queries for reporting. The joins can be divided into the following queries −
Inner Join
This join returns rows when there is a complete match in both the tables.
Table - 1
| OrderID |
CustomerID |
OrderDate |
| 1308 |
2 |
18-09-16 |
| 1009 |
17 |
19-09-16 |
| 1310 |
27 |
20-09-16 |
Table - 2
| CustomerID |
CustomerName |
ContactName |
Country |
| 1 |
Andy |
Maria |
Germany |
| 2 |
Ana |
Ana T |
Canada |
| 3 |
Jason |
Jason |
Mexico |
The Inner join result on Table 1 and Table 2 on the CustomerID column will produce the following result −
| OrderID |
CustomerName |
OrderDate |
| 1308 |
Ana |
09-18-16 |
Left Outer Join
A left outer join, or left join, results in a set where all of the rows from the first, or left hand side, table are preserved. The rows from the second, or right hand side table only show up if they have a match with the rows from the first table.
Table – 1
| gid |
first_name |
last_name |
birthday |
favorite_tool |
| 1 |
Albert |
Einstein |
1879-03-14 |
mind |
| 2 |
Albert |
Slater |
1973-10-10 |
singlet |
| 3 |
Christian |
Slater |
1969-08-18 |
spade |
| 4 |
Christian |
Bale |
1974-01-30 |
videotapes |
| 5 |
Bruce |
Wayne |
1939-02-19 |
shovel |
| 6 |
Wayne |
Knight |
1955-08-07 |
spade |
Table – 2
| pid |
gardener_id |
plant_name |
fertilizer |
planting_date |
| 1 |
3 |
rose |
yes |
2001-01-15 |
| 2 |
5 |
daisy |
yes |
2020-05-16 |
| 3 |
8 |
rose |
no |
2005-08-10 |
| 4 |
9 |
violet |
yes |
2010-01-18 |
| 5 |
12 |
rose |
no |
1991-01-05 |
| 6 |
1 |
sunflower |
yes |
2015-08-20 |
| 7 |
6 |
violet |
yes |
1997-01-17 |
| 8 |
15 |
rose |
no |
2007-07-22 |
Now, if you apply Left Outer Join on gid = gardener_id, the result will be the following table −
| gid |
first_name |
last_name |
pid |
gardener_id |
plant_name |
| 1 |
Albert |
Einstein |
6 |
1 |
sunflower |
| 2 |
Albert |
Slater |
null |
null |
null |
| 3 |
Christian |
Slater |
1 |
3 |
rose |
| 4 |
Christian |
Bale |
null |
null |
null |
| 5 |
Bruce |
Wayne |
2 |
5 |
daisy |
| 6 |
Wayne |
Knight |
7 |
6 |
violet |
In the same way, you can use the right outer join where all the rows from the right tables are preserved as common rows.
Temporal Join
Temporal Joins are used to map a period of time. At the time of reporting, other InfoProviders handle time-dependent master data in such a way that the record that is valid for a pre-defined unique key date is used each time. You can define Temporal join that contains at least one time-dependent characteristic or a pseudo time-dependent InfoProvider.
Self Join
When a table is joined to itself, which is like you are joining a table twice.
Creating an InfoSet
Go to RSA Workbench and use the Transaction Code: RSA1
Under Modeling → Go to InfoProvider tab → Right click → Create InfoSet.

In next window that comes up, you can fill in the following fields −
- Enter the Technical Name.
- Enter the long name and short name.
Start with the InfoProvider section − Here you can define the object that you want to use while defining an InfoSet. You can select from following object types −
- DataStore Object
- Info Object
- InfoCube

In the next window, change how the InfoSet screen appears. Click on Select InfoProvider option. This will allow you to select the InfoProvider to which data is joined.
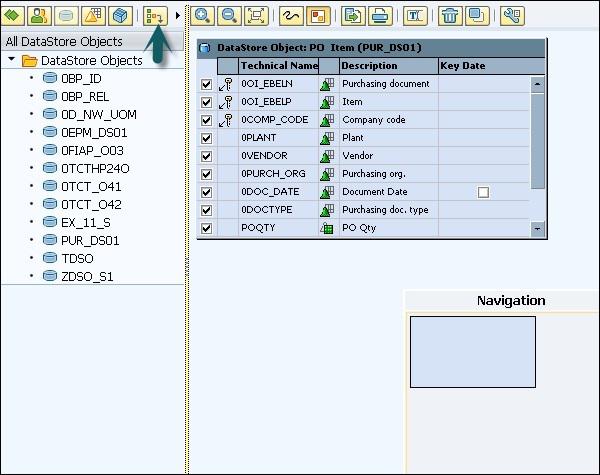

The following screen will appear with two InfoProviders selected.
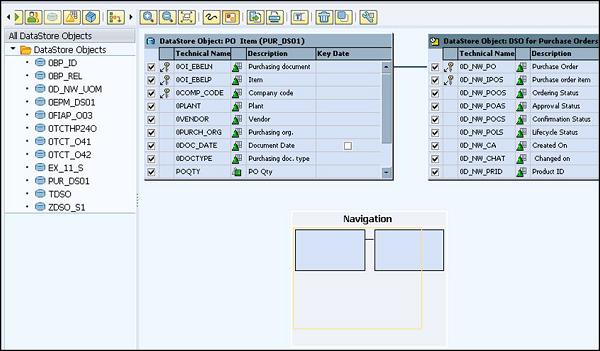
To activate this InfoSet, click on the Activate button.

Editing an Infoset
To edit an Infoset, please use T-Code: RSISET
The Edit InfoSet: Initial Screen appears as shown in the following screenshot −

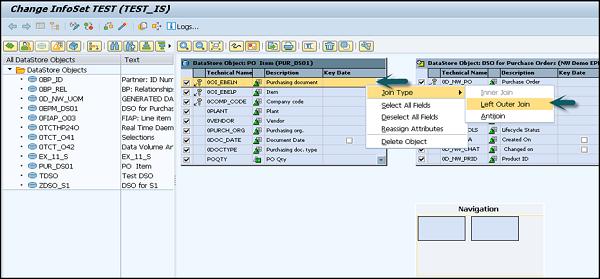
Make the changes to the InfoSet. Select Join type, etc. and then Click on the Activate icon as shown in the following screenshot.
SAP BW - InfoCube
An InfoCube is defined as a multidimensional dataset which is used for analysis in a BEx query. An InfoCube consists of a set of relational tables which are logically joined to implement the star schema. A fact table in the star schema is joined with multiple dimension tables.
You can add data from one or more InfoSource or InfoProviders to an InfoCube. They are available as InfoProviders for analysis and reporting purposes.
InfoCube Structure
An InfoCube is used to store the data physically. It consists of a number of InfoObjects that are filled with data from staging. It has the structure of a star schema.
The real-time characteristic can be assigned to an InfoCube. These Real-time InfoCubes are used differently to standard InfoCubes.
Star Schema in BI
InfoCubes consist of different InfoObjects and are structured according to the star schema. There are large fact tables that contains key figure for InfoCube and multiple smaller dimension tables that surround it.
An InfoCube contains fact tables that further contain key figures and characteristics of an InfoCube that are stored in the dimensions. These dimensions and fact tables are linked to each other using identification numbers (dimension IDs). The key figures in an InfoCube are related to characteristics of its dimension. Granularity (degree of detail) of key figures in an InfoCube is defined by its characteristics.
Characteristics that logically belong together are grouped together in a dimension. The fact table and dimension tables in an InfoCube are both Relational database tables.

In SAP BI, an InfoCube contains Extended Star Schema as shown above.
An InfoCube consists of a fact table which is surrounded by 16 dimension tables and master data that is lying outside the cube. It is a self-enclosed data set encompassing one or more related business processes. A reporting user can define or execute queries against an info cube.
InfoCube stores the summarized / aggregated data for a long period of time. In SAP BI, InfoCubes begins with a number which is usually 0 (zero). Your own InfoCube should begin with a letter between A to Z and that it should be 3 to 9 characters in length.
How to Create an InfoCube?
All InfoObjects to be used in an InfoCube should be available in an active version. In case there is an InfoObject that doesn’t exist, you can create and activate them.
Go to RSA workbench – T-Code: RSA1
Go to Modeling tab → InfoProvider → Create InfoCube.

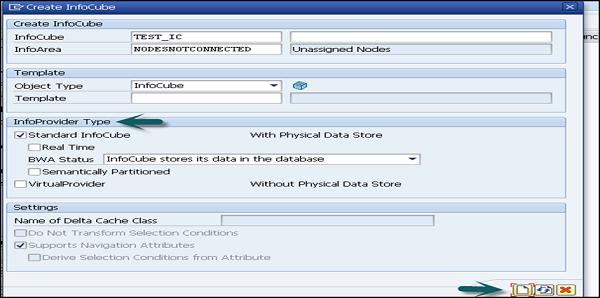
Enter the technical name of the InfoCube. You can select the type from – Standard or Real Time as per the InfoCube type.
Once all this is done, you can click on Create as shown in the following screenshot.
To create a copy of an already existing InfoCube, you can enter an InfoCube as a template.
Right click on Dimension 1 → Properties. Rename the dimension as per the InfoObject.


The next step is to right click on Dimension → InfoObject Direct Input as shown in the following screenshot.

Add InfoObject to dimension. In a similar way you can also create new dimensions and add InfoObjects.

To add Key figures to InfoCube, right click on Key Figure → InfoObject Direct Input. In a similar way you can add other key figures as well.


Once you add all the dimensions and key figures, you can activate the cube.


Real Time InfoCubes
Real time InfoCubes are used to support parallel write access. Real time InfoCubes are used in connection with the entry of planning data.
You can enter the data in Real time InfoCubes in two different ways −
- Transaction for entering planning data or by
- BI Staging
You can also convert a real time InfoCube. To do this, in the context menu of real-time InfoCube → select Convert Real Time InfoCube.
By default, you can see that a Real Time InfoCube can be Planned – Data Loading Not Permitted is selected. To fill this InfoCube using BI staging → Switch this setting to Real Time Cube Can Be Loaded with Data, Planning Not Permitted.
Creating a Real Time InfoCube
A real time InfoCube can be created using a Real Time Indicator check box.

Converting a Standard InfoCube into a Real Time InfoCube
To convert a standard InfoCube to real time InfoCube, you have two options −
Convert with loss of Transactional data − In case your standard InfoCube contains transactional data that is not required, you can use the following approach −
In Administration workbench, select InfoCube → Delete Data Content. This will delete the transaction data and InfoCube will be set to inactive.
Conversion with Retention of Transaction Data − In case a standard InfoCube already contains the transactional data from production, you can use the following steps −
You have to execute ABAP report SAP_CONVERT_NORMAL_TRANS under the standard InfoCube. You can schedule this report as background job for InfoCubes with more than 10,000 data records because the runtime could potentially be long.
SAP BW - Virtual InfoProvider
Virtual InfoProvider is known as InfoProviders that contains transactional data which is not stored in the object and can be read directly for analysis and reporting purposes. In Virtual Provider, it allows read only read access to the data.
The data in Virtual Providers can be from BI system or it can be from any SAP/non-SAP system.
Uses
Virtual InfoProviders are used to provide information without any time lag and without storing the data physically.
Virtual InfoProviders are structures that contains no PSA and they can handle the reporting requirement as per demand in BI system.
Virtual Providers should only be used in the following scenarios −
When there is a need to access only a small amount of data from the source.
Information will be requested by only a few users simultaneously.
There is a need of up-to-date information.
Types of Virtual Providers
As mentioned above, there is a need to find out when a Virtual InfoProvider should be used. You also have to find the correct type of the Virtual Provider −
VirtualProvider Based on the Data Transfer Process
VirtualProvider with BAPI
VirtualProvider with Function Modules
VirtualProvider Based on Data Transfer Process
Virtual Providers based on this method are easiest and the most transparent way to build this type of InfoProvider. In this case, a virtual provider can be based on a DataSource for direct access or on another InfoProvider.
Either the BEx query is executed or you navigate inside the query. But, a request is sent through the virtual provider to its source and the needed data is returned back. For the performance optimization, it is necessary to restrict the data, so that a reporting request shouldn’t process unnecessary data from the source system.
A VirtualProvider based on this InfoProvider should be used −
When there is a need to access only a small amount of data from the source.
Information will be requested by only a few users simultaneously.
There is a need of up-to-date information.
This type of a Virtual InfoProvider shouldn’t be used in the following scenarios −
A large amount of data is accessed in the first query navigation step, and no appropriate aggregates are available in the source system.
There are multiple users who execute queries at the same time at parallel.
When the same data is accessed frequently.

VirtualProvider with BAPI
In this Virtual Provider, you can use the transactional data for analysis and reporting purpose from external system using BAPI. When using a VirtualProvider with BAPI, you can perform reporting on external system without storing the transactional data in the BI system.
A query is executed on VirtualProvider that triggers a data request with characteristic selections. The source structure is dynamic and is determined by the selections. The non-SAP system transfers the requested data to the OLAP processor using the BAPI.
When this VirtualProvider is used for reporting, it initiates a request to call BAPI that collects the data and then it is passed to a BW OLAP engine.
Virtual Provider Based on Functional Module
This is the most complex type of a VirtualProvider but at the same time it is also more flexible using which you can add data from the source and also can apply complex calculations or any changes before it is pushed to the OLAP engine.
You have a number of options for defining the properties of the data source more precisely. According to these properties, the data manager provides various function module interfaces for converting the parameters and data. These interfaces have to be implemented outside the BI system.
Uses
This Virtual Provider is used where you need to display data from a non BI data source in BI without copying dataset in BI structure. The data can be local or remote.
This is used in SAP applications like SAP Strategic Enterprise Management SEM application.
If you compare this VirtualProvider with other types, this VirtualProvider is more flexible, more generic but you have to put lot of effort for implementation.
Using InfoObjects as Virtual Providers
In this you allow a direct access to the source system for an InfoObject type of a characteristic that you have selected for use as an InfoProvider. So there is no need to load the master data, however direct access can have negative impact on query performance.
How to setup InfoObjects as Virtual Providers?
Go to InfoObjects Maintenance page. On the tab page Master data/texts, assign an InfoArea to a characteristic and select direct as type of master data access.
Next is to go the modeling tab, select the InfoProvider tree. Navigate to InfoArea that you want to use → Create Transformation as mentioned in the Transformation topic.

Define Transformation rules and activate. In the context menu, click Create Data Transfer Process (DTP for direct access is default value) → Select the source and activate the transfer process.
SAP BW - MultiProvider
A MultiProvider is known as an InfoProvider that allows you to combine data from multiple InfoProviders and makes it available for reporting purposes.
Features
A MultiProvider doesn’t contain any data for reporting and analysis comes from InfoProviders directly on which the MultiProvider is based.
These InfoProviders are connected with each other by a Union operation.
You can report and analyze the data based on multiple InfoProviders.
MultiProvider Structure
A MultiProvider consists of the following different combinations of InfoProvider types −
- InfoObject
- InfoCube
- DataStore Object
- Virtual Provider

To combine the data, a Union operation is used in a MultiProvider. Here, the system constructs the union set of the data sets involved and all the values of these data sets are combined.
In an InfoSet you create the dataset using joins. These joins only combine values that appear in both tables. As compared to a Union, joins form the intersection of the tables.
Creating a MultiProvider
To create a MultiProvider using an InfoObject, each InfoObject that you want to transfer to the MultiProvider should be in an active state. If there is an InfoObject that doesn’t exist, then you need to create it and activate the same.
You can also install a MultiProvider from SAP Business Content if you don’t want to create a new MultiProvider.
To create a MultiProvider, you can go through the following steps −

Create an InfoArea to which you want to assign the new MultiProvider. Go to Modeling → InfoProvider
In the context menu of the InfoArea, choose Create MultiProvider.

In the next window, enter a technical name and a description → Create icon

Select the InfoProvider that you want to form the MultiProvider → Continue. Then the MultiProvider screen appears.

Use drag and drop to transfer the required InfoObjects into your MultiProvider. You can also transfer the entire dimensions.

Use Identify Characteristics and Select Key Figures to make InfoObject assignments between MultiProvider and InfoProvider.
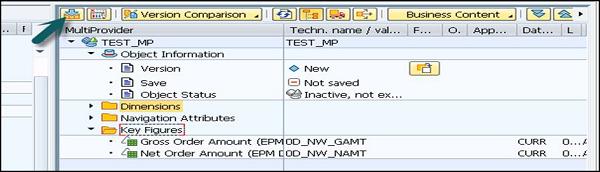
The next step is to save and activate the MultiProvider and only this activated MultiProvider will be available for reporting and analysis.
SAP BW - Flat File Data Transfer
You can load the data from an external system to BI using these flat files. SAP BI supports data transfer using flat files, files in ASCII format, or in the CSV format.
The data from a flat file can be transferred to BI from a workstation or from an application server.
Following are the steps involved in a Flat File Data Transfer −
Define a file source system.
Create a DataSource in BI, defining the metadata for your file in BI.
Create an InfoPackage that includes the parameters for data transfer to the PSA.
Important Points about Flat File Data Transfer
If there are character fields that are not filled in a CSV file, they are filled with a blank space and with a zero (0) if they are numerical fields.
If separators are used inconsistently in a CSV file, the incorrect separator is read as a character and both fields are merged into one field and may be shortened. Subsequent fields are then no longer in the correct order.
A line break cannot be used as part of a value, even if the value if enclosed with an escape character.
A couple of pointers with regard to the CSV and ASCII files
The conversion routines that are used to determine whether you have to specify leading zeros. More information − Conversion Routines in the BI-System.
For dates, you usually use the format YYYYMMDD, without internal separators. Depending on the conversion routine being used, you can also use other formats.
Define a File Source System
Before you can transfer data from a file source system, the metadata must be available in BI in the form of a DataSource. Go to Modeling tab → DataSources.

Right click in context area → Create DataSource.

Enter the technical name of the data source, type of data source and then click on Transfer.

Go to General tab → Select the General Tab. Enter descriptions for the DataSource (short, medium, long).
If required, specify whether the DataSource is initial non-cumulative and might produce duplicate data records in one request.
You can specify whether you want to generate the PSA for the DataSource in the character format. If the PSA is not typed it is not generated in a typed structure but is generated with character-like fields of type CHAR only.

The next step is to click on the Extraction tab page and enter the following details −
Define the delta process for the DataSource. Specify whether you want the DataSource to support direct access to data (Real-time data acquisition is not supported for data transfer from files).
Select the adapter for the data transfer. You can load text files or binary files from your local work station or from the application server. Select the path to the file that you want to load or enter the name of the file directly.
In case you need to create a routine to determine the name of your file. The system reads the file name directly from the file name field, if no, then the routine is defined.
As per the adapter and the file to be loaded, the following setting has to be made −

Binary files − Specify the character record settings for the data that you want to transfer.
Text-type files − For text files, determine the rows in your file are header rows and they can therefore be ignored when the data is transferred. Specify the character record settings for the data that you want to transfer.
For ASCII files − To load the data from an ASCII file, the data is requested with a fixed data record length.
For CSV files − To load data from an Excel CSV file, mention the data separator and the escape character.
The next step is to go to the Proposal tab page, this is required only for CSV files. For files in different formats, define the field list on the Fields tab page.

The next step is to go to Fields tab −
You can edit the fields that you transferred to the field list of the DataSource from the Proposal tab. If you did not transfer the field list from a proposal, you can define the fields of the DataSource here as shown in the following screenshot.

You can then perform check, save and activate the DataSource.
You can also select the Preview tab. If you select read Preview Data, the number of data records you specified in your field selection is displayed in a preview.

SAP BW - DB Connect
DB Connect is used to define other database connection in addition to the default connection and these connections are used to transfer data into the BI system from tables or views.
To connect an external database, you should have the following information −
- Tools
- Source Application knowledge
- SQL syntax in Database
- Database functions
Perquisites
In case the source of your Database management system is different from BI DBMS, you need to install database client for source DBMS on the BI application server.
DB Connect key feature includes loading of data into BI from a database that is supported by SAP. When you connect a database to BI, a source system requires creating a direct point of access to the external relational database management system.
DB Architecture
SAP NetWeaver component’s multiconnect function allows you to open extra database connections in addition to the SAP default connection and you can use this connection to connect to external databases.
DB Connect can be used to establish a connection of this type as a source system connection to BI. The DB Connect enhancements to the database allows you to load the data to BI from the database tables or views of the external applications.

For default connection, the DB Client and DBSL are preinstalled for the database management system (DBMS). To use DB Connect to transfer data into the BI system from other database management systems, you need to install database-specific DB Client and database-specific DBSL on the BI application server that you are using to run the DB Connect.
Creating DBMS as Source System
Go to RSA1 → Administration workbench. Under the Modeling Tab → Source Systems

Go to DB Connect → Right click → Create.

Enter the logical system name (DB Connect) and description. Click on Continue.

Enter the database management system (DBMS) that you want to use to manage the database. Then enter the database user under whose name you want the connection to be opened and the DB Password has to enter for authentication by the database.
In the Connection Info, you have to enter the technical information required to open the database connection.
Permanent Indicator
You can set this indicator to keep a permanent connection with the database. If the first transaction ends, then each transaction is checked to see if the connection has been reinitiated. You can use this option if the DB connection has to be accessed frequently.
Save this configuration and you can Click Back to see it in the table.
SAP BW - Universal Data Connect
Universal Data Connect (UDC) allows you to access relational and multidimensional data sources and transfer the data in the form of flat data. Multidimensional data is converted to a flat format when the Universal Data Connect is used for data transfer.
UD uses a J2EE connector to allow reporting on SAP and non-SAP data. Different BI Java connectors are available for various drivers, protocols as resource adapters, some of which are as follows −
- BI ODBO Connector
- BI JDBC Connector
- BI SAP Query Connector
- XMLA Connector
To set up the connection to a data source with source object (Relational/ OLAP) on J2EE engine. Firstly, you have to enable communication between the J2EE engine and the BI system by creating RFC destination from J2EE to BI. Then model the InfoObjects in BI as per the source object elements, and in the BI system determine the data source.
Creating a UD Connect Source System
As mentioned above, you have created an RFC destination through which the J2EE engine and BI allows communication between these two systems.
Go to Administration workbench, RSA1 → Go to Modeling tab → Source Systems.

Right click on the UD Connect → Create. Then in the next window, enter the following details −
- RFC Destination for the J2EE Engine
- Specify a logical system name
- Type of connector

Then you should enter the −
- Name of the connector.
- Name of the source system if it was not determined from the logical system name.
Once you fill in all these details → Choose Continue.

SAP BW - Process Chain
In SAP BI Data Warehouse Management, it is possible to schedule a sequence of processes in the background for an event and few of these processes can trigger a separate event to start the other processes.
A process chain provides the following benefits to you in a SAP BI system −
They can be used to centrally manage and control the processes.
You can visualize the processes by using graphics.
Using event controlled processing, you can automate the complex schedules.
Features −
- Security
- Flexibility
- Openness
Structure of a Process Chain
Each process chain consists of the following components −
- Start Process
- Individual application Processes
- Collection Processes
The start process is used to define the start condition of a process chain and all other chain processes are scheduled to wait for an event. The application processes are the processes that are defined in a sequence and are the actual processes in a BI system. They can be categorized as −
- Load Process
- Reporting agent Process
- Data target administration process
- Other BI processes

A Process can be defined as a procedure inside or external to the SAP system and has a definite beginning and end.
Start Process for Designing a Process Chain
The start process is used to define the start condition of a process chain. You can start a process chain at the specified time or after an event that is triggered by a start process.
A start of the process chain can also be configured using a metachain. If the start condition of a process chain is integrated with another process chain, this is known as a metachain.
Following are the key features of a Start Process −
In a process chain, only a start process can be scheduled without a predecessor process.
You can define only one start process for each process chain.
A start process can’t be a successor of another process.
You can use a start process only in a single process chain.
How to Create a Process chain?
Use T-Code: RSPC or in the Modeling tab → Go to Process Chain.

Right Click in the Context area → Create Process Chain.

Enter the technical name and the description of the Process chain. Click Continue.

To create a Start process, click on the new icon in the next window that comes up. Enter the technical name and the description of the star process.


In the next window, you can define the scheduling options. Direct scheduling is to schedule the process chain at a specified time interval.
You can use “Change selection” to enter details of the scheduling.

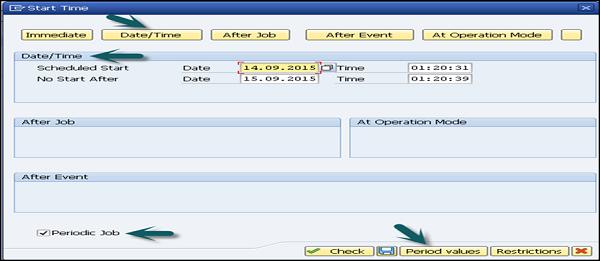
Go to Date/Time button. Mention the Scheduled Start date/time, end date/time.
To define frequency, select the check box Periodic Job as shown in the following screenshot. Click on Period Values. Enter the frequency (Hourly/Daily/Weekly/Monthly/Other Period). Click on Save and back button to go back to the previous RSPC screen.


The next step is to select the Process type.
To perform dataload via an InfoPackage, use the Process Type Execute InfoPackage.
To perform dataload via a DTP, use the Process Type Data Transfer Process.

Double click on the process type and a new window will open. You can select InfoPackage from the options given.

To connect the variant with an InfoPackage, Select the “Start Variant” and keep the left mouse button pressed. Then move the mouse button to the target step. An arrow should follow your movement. Stop pressing the mouse button and a new connection is created.
To perform a consistency check, Click Goto → Checking View.


To activate the process chain, click on Activate or see the following screenshot for understanding the steps to be adhered to.

To schedule the process chain, go to Execution → Schedule. Select Priority and Continue.

This will schedule the process chain as a background job and can be viewed using Transaction SM37.
Monitor the Process Chain
Use T-Code: RSPCM
This is used to monitor daily process chains.

To view the logs, use T-code: RSPC
Select Process chain → Right Click → Display Log.

SAP BW - Reporting
In a SAP BI system, you can analyze and report on the selected InfoProviders data using drag and drop or context menu to navigate in the queries created in the BEx query designer.
In Today’s competitive market, the most successful companies respond quickly and flexibly to market changes and opportunities. A key to this response is the effective and efficient use of data and information by analysts and managers. A “Data Warehouse” is a repository of historical data that are organized by subject to support decision makers in the organization. Once data are stored in a data mart or warehouse, they can be accessed.
In SAP BI, Business Explorer (BEx) is one of the key component that allows you to perform flexible reporting and analysis and provides different tools that can be used for strategic analysis and supporting the decision makers in taking decision for future strategy.
The most common tools included in BEx are −
- Query
- Reporting
- Analysis Functions
Following are the key components in a Business Explorer −
- BEx Query Designer
- BEx Web Application Designer
- BEx Broadcaster
- BEx Analyzer
BEx Query Designer
In BEx Query Designer, you can analyze the data in BI system by designing queries for InfoProvider. You can combine InfoObjects and query elements that allows you to navigate and analyze the data in the InfoProvider.
BEx Query Designer Key Functions
You can use queries in the BEx Query Designer for OLAP reporting and for enterprise reporting.
Queries can contain different parameters like variables for characteristic values, hierarchies, formulas, text, etc.
You can select InfoObjects more precisely by −
In the Query Designer, you can apply a filter to restrict the whole query. While defining the filter, you can add characteristic values from one or more characteristics or also key figures in the filter. All of the InfoProvider data is aggregated using the filter selection of the query.
You can also use user-defined characteristics and determine the content of the rows and columns of the query. This is used to specify the data areas of the InfoProvider through which you want to navigate.
You have an option of navigating through the query that allows you to generate different views of the InfoProvider data. This can be achieved by dragging any of user defined characteristics into the rows or columns of the query.

How to Access Query Designer?
To access BEx query designer, go to Start → All Programs.

In the next step, select BI system → OK.

Enter the following details −
- Enter the Client
- User Name
- Password
- Logon Language
- Click the Ok Button

You can see the following components in a Query Designer −
InfoProvider Details are available here.
Tabs to view various report components.
Properties Box which shows the properties of each component selected in the query.

The Standard tool bar in the Query Designer shown at the top has the following buttons.
- Create New Query
- Open Query
- Save Query
- Save All
- Query Properties
- Publish on Web
- Check Query, and many other options.
Query Elements in InfoProvider
Key figures − It contains the numerical data or measures or Key Performance Indicators KPI’s and can be further divided into Calculated Key figures CKF’s and Restricted Key Figures RKF’s.
Characteristics − They define the criteria to classify the objects. For example: Product, Customer, Location, etc.
Attributes − They define the additional properties of a characteristics.
Query Properties
Variable Sequence − It is used to control the order in which selection screen variables are displayed to users.

Display − Go to Display tab to set the display properties as follows −
Hide Repeated Key Values − It is used to control the characteristics that will repeat in each row or not.
Display Scaling Factors for Key Figures − It is used to control whether the scaling factor is reported at the top of corresponding column.
You can also define filters, use Variables in the Query designer. These filters are used to limit the data access in reporting, analysis to a certain business sector, product group, or time period.
Variables
Variables are defined as parameters of a query in the Query Designer that are filled with values when you execute the query. Different types of Variables can be created, some of which are as follows −
- Hierarchy Variables
- Characteristics Value Variables
- Text Variable
- Formula Variable
- Hierarchy node variables
To create a variable, go to the folder Characteristic Value Variables available under the corresponding characteristic.
The next step is to right click on the folder → select the option New Variable.
Restricted Key Figures
It is also possible to restrict the key figures of an InfoProvider for reuse by selecting one or more characteristics. You can restrict the key figures by one or more characteristic selections and it can be basic key figures, calculated key figures, or key figures that are already restricted.
To create a new restricted key figure, In the InfoProvider screen area → select the Key Figures entry and choose New Restricted Key Figure from the context menu.
Restricted Characteristics −
- Selecting single values
- Selecting value ranges
- Saving values to favorites
- Displaying value keys
- Values available in history
- Deleting values from the selection window
BEx Analyzer: Reporting and Analysis
BEx Analyzer is known as a design tool embedded in Microsoft Excel and used for reporting and analysis. In a BEx Analyzer, you can analyze and plan with selected InfoProvider data using the context menu or drag and drop to navigate in queries created in the BEx Query Designer.
BEx Analyzer is divided into two modes for different purposes −
Analysis mode − It is used for executing OLAP analyses on queries.
Design mode − It is used for designing the interface for query applications.
Analysis Mode
You can perform the following tasks in the Analysis mode −
You can access the BEx Query Designer to define queries.
You can analyze the InfoProvider data by navigating in the queries.
You can use different functions like sorting, filtering, drilling etc. that are common in OLAP.
Distribution of workbooks with BEx Broadcaster.
For advanced programming you can embed your own customized VBA programs.
You can save workbooks on the server/locally on your computer or into favorites.
Design Mode
You can perform the following tasks in the design mode −
It can be used to design the query and you can embed different query design items like dropdown boxes, radio button groups, grid and buttons into your Microsoft Excel workbook.
You can also customize your workbook with Excel’s formatting and chart functionality.
To start BEx Analyzer, from the Windows Start menu, choose Programs → Business Explorer → Analyzer.