YAML - Processes
YAML follows a standard procedure for Process flow. The native data structure in YAML includes simple representations such as nodes. It is also called as Representation Node Graph.
It includes mapping, sequence and scalar quantities which is being serialized to create a serialization tree. With serialization the objects are converted with stream of bytes.
The serialization event tree helps in creating presentation of character streams as represented in the following diagram.
The reverse procedure parses the stream of bytes into serialized event tree. Later, the nodes are converted into node graph. These values are later converted in YAML native data structure. The figure below explains this −
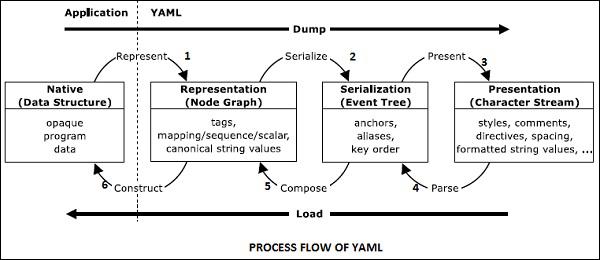
The information in YAML is used in two ways: machine processing and human consumption. The processor in YAML is used as a tool for the procedure of converting information between complementary views in the diagram given above. This chapter describes the information structures a YAML processor must provide within a given application.
YAML includes a serialization procedure for representing data objects in serial format. The processing of YAML information includes three stages: Representation, Serialization, Presentation and parsing. Let us discuss each of them in detail.
Representation
YAML represents the data structure using three kinds of nodes: sequence, mapping and scalar.
Sequence
Sequence refers to the ordered number of entries, which maps the unordered association of key value pair. It corresponds to the Perl or Python array list.
The code shown below is an example of sequence representation −
product:
- sku : BL394D
quantity : 4
description : Football
price : 450.00
- sku : BL4438H
quantity : 1
description : Super Hoop
price : 2392.00
Mapping
Mapping on the other hand represents dictionary data structure or hash table. An example for the same is mentioned below −
batchLimit: 1000
threadCountLimit: 2
key: value
keyMapping: <What goes here?>
Scalars
Scalars represent standard values of strings, integers, dates and atomic data types. Note that YAML also includes nodes which specify the data type structure. For more information on scalars, please refer to the chapter 6 of this tutorial.
Serialization
Serialization process is required in YAML that eases human friendly key order and anchor names. The result of serialization is a YAML serialization tree. It can be traversed to produce a series of event calls of YAML data.
An example for serialization is given below −
consumer:
class: 'AppBundle\Entity\consumer'
attributes:
filters: ['customer.search', 'customer.order', 'customer.boolean']
collectionOperations:
get:
method: 'GET'
normalization_context:
groups: ['customer_list']
itemOperations:
get:
method: 'GET'
normalization_context:
groups: ['customer_get']
Presentation
The final output of YAML serialization is called presentation. It represents a character stream in a human friendly manner. YAML processor includes various presentation details for creating stream, handling indentation and formatting content. This complete process is guided by the preferences of user.
An example for YAML presentation process is the result of JSON value created. Observe the code given below for a better understanding −
{
"consumer": {
"class": "AppBundle\\Entity\\consumer",
"attributes": {
"filters": [
"customer.search",
"customer.order",
"customer.boolean"
]
},
"collectionOperations": {
"get": {
"method": "GET",
"normalization_context": {
"groups": [
"customer_list"
]
}
}
},
"itemOperations": {
"get": {
"method": "GET",
"normalization_context": {
"groups": [
"customer_get"
]
}
}
}
}
}
Parsing
Parsing is the inverse process of presentation; it includes a stream of characters and creates a series of events. It discards the details introduced in the presentation process which causes serialization events. Parsing procedure can fail due to ill-formed input. It is basically a procedure to check whether YAML is well-formed or not.
Consider a YAML example which is mentioned below −
---
environment: production
classes:
nfs::server:
exports:
- /srv/share1
- /srv/share3
parameters:
paramter1
With three hyphens, it represents the start of document with various attributes later defined in it.
YAML lint is the online parser of YAML and helps in parsing the YAML structure to check whether it is valid or not. The official link for YAML lint is mentioned below: http://www.yamllint.com/
You can see the output of parsing as shown below −