Инструменты анализа и проектирования программного обеспечения
Анализ и конструкция програмного обеспечения включают все работы, которые помогают преобразованию спецификации требования в вставку. Спецификации требования определяют все функциональные и нефункциональные ожиданности от програмного обеспечения. Эти спецификации требования приходят в форме людских четких и постижимых документов, к которым компьютер не имеет ничего сделать.
Анализ и конструкция програмного обеспечения промежуточный этап, который помогает людск-четким требованиям быть преобразованным в фактический Код.
Препятствуйте нам увидеть немного анализ и инструментам для конструирования используемым конструкторами програмного обеспечения:
Диаграмма потока информации
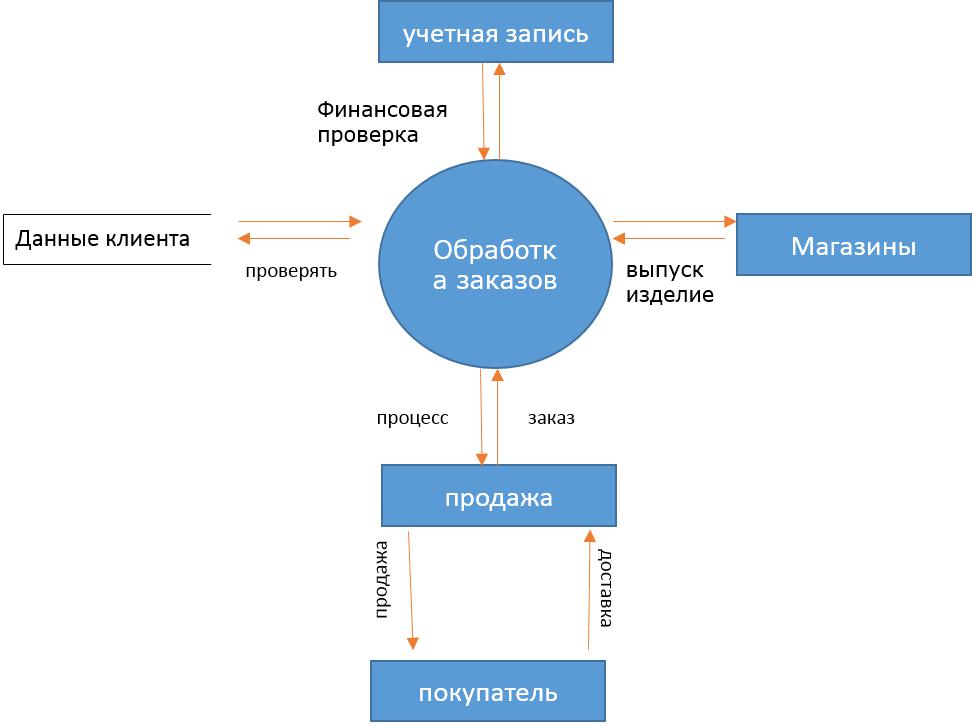
Диаграмма потока информации графическое представление подачи данных в информационной системе. Она способна показывать входящий поток информации, общительный поток информации и хранящиеся данные. DFD не упоминает что-нибыдь о как потоки информации через систему.
Видно разница между DFD и схемой технологического процесса. Схема технологического процесса показывает подачу управления в модулях программы. DFDs показывает подачу данных в системе на различных уровнях. DFD не содержит никакое управление или не разветвляет элементы.
Типы DFD
Графические представления диаграммы данных или логически или физически.
Логически DFD - Этот тип DFD концентрирует на процессе системы, и подаче данных в системе. Например в программной системе банка, как данные двинуты между различными реальностями.
Физические DFD - Этот тип DFD показывает как поток информации фактически снабжен в системе. Он более специфическ и близко к вставке.
Компоненты DFD
DFD может представить источник, назначение, хранение и подачу данных используя следующий комплект компонентов -

Реальности - реальности источник и назначение данных по информации. Реальности представлены прямоугольники с их соответственно именами.
Процесс - деятельности и действие принятые на данные представлены кругом или Кругл-окаимленными прямоугольниками.
Хранение данных - 2 варианта хранения данных - его можно или представить как прямоугольник с отсутствием обеих более малых сторон или как, котор открыт-встали на сторону прямоугольник с только одним бортовым отсытствием.
Поток информации - показывают движение данных остроконечными стрелками. Показывают движение данных от основания стрелки как свой источник к головке стрелки как назначение.
Уровни DFD
Уровень 0 - Самый высокий уровень DFD абстракции как уровень 0 DFD, который показывает всю информационную систему как одна диаграмма скрывая все основные детали. Уровень 0 DFDs также как уровень DFDs контекста.

Уровень 1 - Уровень 0 DFD сломленный спуск в специфическое, уровень 1 DFD. Уровень 1 DFD показывает основные модули в системе и подаче данных среди различных модулей. Уровень 1 DFD также упоминает основные процессы и источники информации.
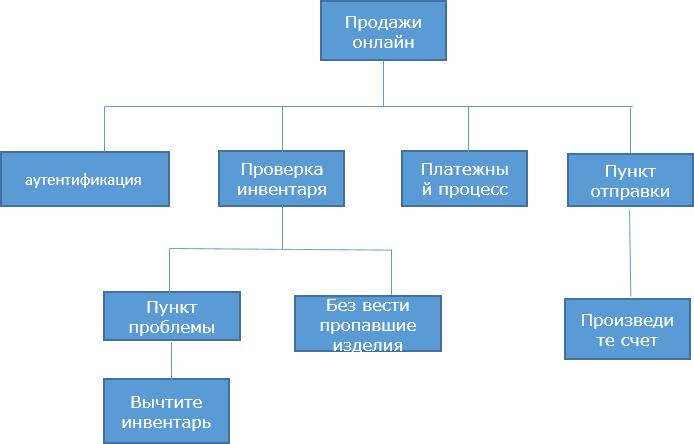
Уровень 2 - На этом уровне, DFD показывает как потоки информации внутри упомянутых модулей в уровне 1.
Более высокий уровень DFDs можно преобразовать в более специфический lower level DFDs с более глубоким уровнем понимать если не достиган пожеланный уровень спецификации.
Диаграммы структуры
Диаграмма структуры диаграмма выведенная от диаграммы потока информации. Она представляет систему более подробно чем DFD. Она ломает вниз с всей системы в самые низкие функциональные модули, описывает функции и sub-функции каждого модуля системы к большой детали чем DFD.
Диаграмма структуры представляет иерархическаяо структура модулей. На каждом слое специфическая задача выполнена.
Здесь символы используемые в конструкции диаграмм структуры -
Модуль - он представляет процесс или подпрограмму или задачу. Отсек управления разветвляет до больше чем один подмодуль. Модули архива многоразовы и invokable от любого модуля.

Условие - оно представлен малым диамантом на основании модуля. Оно показывает что отсек управления может выбрать любую из подпрограммы основанной на некотором условии.

Скачка - показывают стрелке указывать внутри модуля, котор нужно показать что управление поскачет в середине подмодуля.

Петля - изогнутая стрелка представляет петлю в модуле. Все подмодули предусматриванные петлей повторяют исполнение модуля.

Поток информации - сразу стрелка с пустым кругом в конце представляет поток информации.

Подача управления - сразу стрелка с заполненным кругом в конце представляет подачу управления.

HIPO Диаграмма
HIPO (Hierarchical Input Process Output) Диаграмма метод сочетание из 2 организованный для того чтобы проанализировать систему и обеспечить середины документации. Модель HIPO была начата IBM в годе 1970.
HIPO Диаграмма представляет иерархию модулей в программной системе. Аналитик использует диаграмму HIPO для того чтобы получить высокопоставленный взгляд функций системы. Она разлагает функции в sub-функции в иерархическом образе. Она показывает функции выполненные системой.
HIPO Диаграммы хороши для цели документации. Их графическое представление делает его более легкой для конструкторов и менеджеров для того чтобы получить наглядную идею структуры системы.
В отличие от диаграммы IPO (ого процесса входного сигнала), которая показывает подачу управления и данных в модуле, HIPO не обеспечивает никакую информацию о подаче потока информации или управления.

Пример
Обе части диаграммы HIPO, иерархического представления и диаграммы IPO использованы для конструкции структуры программы програмного обеспечения так же, как документации этих же.
Составленный английский язык
Большинств программники незнающи большого изображения програмного обеспечения поэтому они только полагаются на чего их менеджеры говорят им сделать. Ответственность более высокого управления програмного обеспечения снабдить точную информацию программники для того чтобы начать точный но быстрый Код.
Другие формы методов, которые используют диаграммы или диаграммы, могут иногда интерпретированы по-разному различными людьми.
Следовательно, аналитики и конструкторы програмного обеспечения приходят вверх с инструментами как составленный английский язык. Ничего но описание что необходимы, что кодирует и как закодировать его. Составленный английский язык помогает программнику написать безошибочный Код.
Другая форма методов, которые используют диаграммы или диаграммы, может иногда интерпретирована по-разному различными людьми. Здесь, и составленный английский язык и псевдокод пробуют mitigate то понимая зазор.
Составленный английский язык оно использует простые английские слова в составленной программируя парадигме. Нет не типичный Код а вид описания что необходимы, что кодируют и как закодировать его. Следующие некоторые знаки внимания составленный программировать.
IF-THEN-ELSE,
DO-WHILE-UNTIL
Аналитик использует такие же переменную величину и данные - имя, которые хранятся в словаре данных, делая их гораздо простее написать и понять Код.
Пример
Мы принимаем такой же пример удостоверения подлинности клиента в он-лайн окружающей среде покупкы. Этой процедуре для аутентификации клиента можно написать в составленном английском языке как:
Enter Customer_Name
SEEK Customer_Name in Customer_Name_DB file
IF Customer_Name found THEN
Call procedure USER_PASSWORD_AUTHENTICATE()
ELSE
PRINT error message
Call procedure NEW_CUSTOMER_REQUEST()
ENDIF
Код написанный в составленном английском языке больше как межсуточный поговоренный английский язык. Его нельзя снабдить сразу как Код програмного обеспечения. Составленный английский язык независимый языка программирования.
Псевдокод
Пишут псевдо Коду больше близко к языку программирования. Он может быть рассмотрен как увеличенный язык программирования, полный комментариев и описаний.
Псевдо Код во избежание переменное объявление но они написаны используя некоторые фактические стройки языка программирования, как c, Fortran, Паскаль etc.
Псевдо Код содержит больше программируя деталей чем составленный английский язык. Он обеспечивает метод для того чтобы выполнить задачу, если компьютер исполняет Код.
Пример
Программа для того чтобы напечатать Фибоначчи до номеров n.
void function Fibonacci
Get value of n;
Set value of a to 1;
Set value of b to 1;
Initialize I to 0
for (i=0; i< n; i++)
{
if a greater than b
{
Increase b by a;
Print b;
}
else if b greater than a
{
increase a by b;
print a;
}
}
Таблицы решений
Таблица решений представляет условия и соответственно действия, котор нужно принять для того чтобы адресовать их, в составленном таблитчатом формате.
Это мощный инструмент для того чтобы отлаживать и предотвратить ошибки. Оно помогает данным по группы подобным в одиночную таблицу и после этого путем совмещать таблицы она поставляет легкое и удобное принятие решений.
Создавать таблицу решений
Для того чтобы создать таблицу решений, проявитель должен следовать основными 4 шагами:
- Определите все возможные условия, котор нужно адресовать
- Определите действия для всех определенных условий
- Создайте максимальные возможные правила
- Определите действие для каждого правила
Таблицы решений должны быть подтвержены пользователями и могут в последнее время быть упрощены путем исключать двойные правила и действия.
Пример
Препятствуйте нам принять простой пример межсуточной проблемы с нашим взаимодействием интернета. Мы начинаем путем определять все проблемы которые могут возникнуть пока начинающ интернет и их соответственно возможные разрешения.
Мы перечисляем все возможные проблемы под условиями колонки и предполагаемые действия под действиями колонки.
|
Условия/действия |
Правила |
| Условия |
Соединенные выставки |
N |
N |
N |
N |
Y |
Y |
Y |
Y |
| Пинг работает |
N |
N |
Y |
Y |
N |
N |
Y |
Y |
| Раскрывает вебсайт |
Y |
N |
Y |
N |
Y |
N |
Y |
N |
| Действия |
Проверите кабель сети |
X |
|
|
|
|
|
|
|
| Проверите маршрутизатор интернета |
X |
|
|
|
X |
X |
X |
|
| Повторите старт браузера паутины |
|
|
|
|
|
|
X |
|
| Контактируйте сервис-провайдер |
|
X |
X |
X |
X |
X |
X |
|
| Не сделайте никакое действие |
|
|
|
|
|
|
|
|
Таблица : Таблица решений - внутренняя диагностика интернета
Модель Реальност-Отношения
Модель Реальност-Отношения тип модели базы данных основанный на придумке реальностей реального мира и отношении среди их. Мы можем составить карту сценарий реального мира на модель базы данных ER. Модель ER создает комплект реальностей с их атрибутами, комплект ограничений и отношение среди их.
ER Model is best used for the conceptual design of database. ER Model can be represented as follows:

объект - Предприятие в Модели ER - реальный мир быть, у которого есть некоторые свойства, названные признаки. Каждый признак определен его соответствующим набором ценностей, названных область.
Например, Рассмотрите школьную базу данных. Здесь, студент - предприятие. У студента есть различные признаки как name, id, age and class etc.
Отношения - логическая ассоциация среди предприятий называют отношениями. Отношения нанесены на карту с предприятиями различными способами. Наносящие на карту количества элементов определяют число ассоциаций между двумя предприятиями.
Отображение количеств элементов:
- один к одному
- один многим
- многие к одному
- многие многим
Словарь Данных
Словарь данных - централизованная коллекция информации о данных. Это хранит значение и происхождение данных, его отношений с другими данными, форматом данных для использования и т.д. У словаря данных есть строгие определения всех имен, чтобы облегчить пользователя и разработчиков программного обеспечения.
На словарь данных часто ссылаются как метаданные (данные о данных) хранилище. Это создано наряду с моделью DFD (Data Flow Diagram) программы и, как ожидают, будет обновлено каждый раз, когда DFD изменен или обновлен.
требование словаря данных
На данные ссылаются через словарь данных, проектируя и осуществляя программное обеспечение. Словарь данных удаляет любые возможности двусмысленности. Это помогает работе хранения программистов и проектировщиков, синхронизированных, используя ту же самую объектную ссылку везде в программе.
Словарь данных обеспечивает способ документации для полной системы базы данных в одном месте. Проверка DFD выполнена, используя словарь данных.
Содержание
Словарь данных должен содержать информацию о следующем
- Поток данных
- Структура данных
- Элементы Данных
- Хранилища данных
- Обработка данных
Поток данных описан посредством DFDs, как изучено ранее и представлен в алгебраической форме, как описано.
| = |
Составленный из |
| {} |
повторение |
| () |
дополнительный |
| + |
и |
| [ / ] |
или |
пример
Адрес = Дом No + (улица / область) + Город + государство
ID курса = число курса + имя курса + уровень курса + оценки за курс
Элементы Данных
Элементы данных состоят из Имени и описаний Пунктов Данных и Контроля, Внутренние или Внешние хранилища данных и т.д. со следующими деталями:
- Основное Имя
- Вторичное Имя (Псевдоним)
- Случай использования (Как и где использовать)
- Описание Содержания (Примечание etc. )
- ополнительная информация (заданные ценности, ограничения etc.)
Хранилище данных
Это хранит информацию от того, где данные вступают в систему и существуют из системы. Хранилище данных может включать -
- Файлы
- Внутренний к программному обеспечению.
- Внешний к программному обеспечению, но на той же самой машине.
- Внешний к программному обеспечению и системе, расположенной на различной машине.
таблица
- соглашение Обозначения
- собственность Индексации
Обработка данных
Есть два типа Обработки данных:
