IMS DB - Indexação Secundário
Indexação secundário é usado quando queremos acessar um banco de dados sem usar a chave concatenada completa ou quando a gente não quer usar a seqüência campos primários.
Segmento Ponteiro do Índice
DL/I armazena o ponteiro para segmentos do índice banco de dados em um banco de dados separado. Ponteiro do Índice segmento é o único tipo de índice secundário. É constituído de duas partes:
- Elemento Prefixo
- Elemento de Dados
Elemento Prefixo
O prefixo parte do ponteiro do índice segmento contém um ponteiro para o índice segmento-alvo. Index segmento-alvo é o segmento que está acessível através do índice secundário.
Elemento de Dados
O elemento de dados contém o valor da chave do segmento no índice banco de dados em que o índice é construído. Isso também é conhecido como o índice segmento de origem.
Aqui estão os pontos-chave a nota sobre Indexação secundária:
O índice segmento de origem e o segmento alvo, a fonte não precisa ser o mesmo.
Quando montamos um índice secundário, ele é automaticamente mantida pela DL/I.
O DBA define muitos índices secundários como por os vários caminhos de acesso. Estes índices secundários são armazenadas em um índice separado banco de dados.
Não devemos criar mais índices secundários, como impor sobrecarga de processamento adicional do DL/I.
As chaves secundárias
Os pontos de observação:
O campo da fonte índice segmento sobre a qual o índice secundário é construída, é conhecida como a chave secundária.
Qualquer campo pode ser usado como uma chave secundária. Não precisa ser os segmentos campo de seqüência.
As chaves secundárias podem ser qualquer combinação de um único índice campos dentro do segmento de origem.
Os valores da chave secundária não têm de ser únicos.
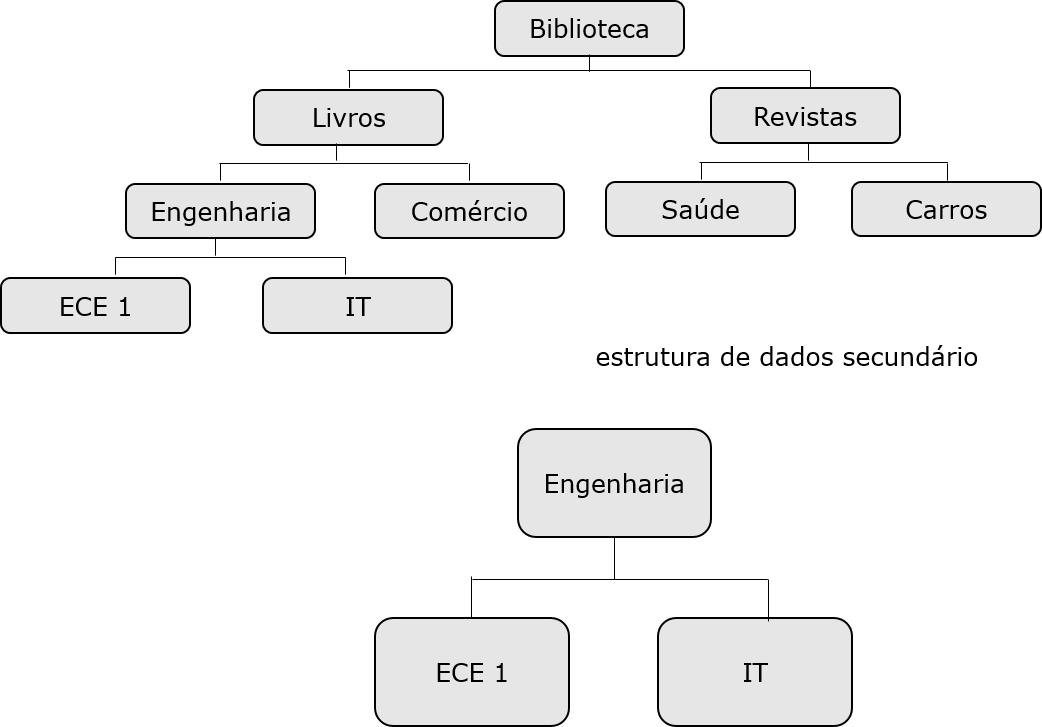
Estruturas de Dados Secundário
Os pontos de observação:
Quando criamos um índice secundário, a aparente estrutura hierárquica da base de dados também é alterada.
O índice segmento-alvo se torna a raiz aparente segmento. Como mostrado na imagem a seguir, o segmento Engenharia segmento torna-se a raiz, mesmo se não for uma raiz segmento.
A reorganização da estrutura da base de dados causado pelo índice secundário é conhecido como secundário estrutura de dados.
As estruturas de dados secundário não fazer quaisquer alterações à estrutura principal banco de dados físico presente no disco. É apenas uma forma de alterar a estrutura do banco na frente do programa aplicativo.
Independente e Operador
Os pontos de observação:
Quando uma E (* or &) operador é usado com índices secundários, é conhecido como um dependente e o operador.
Um independente e (#) permite-nos especificar qualificações de que seria impossível com um dependente E.
Este operador pode ser utilizado apenas para índices secundários onde o índice segmento de origem é dependente do índice segmento-alvo.
Podemos codificar um navio com um independente e de especificar que uma ocorrência do segmento-alvo serão processados com base nos campos de dois ou mais dependentes fonte segmentos.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.
Sequenciamento esparsos
Os pontos de observação:
Sparse seqüenciamento é também conhecido como Sparse indexação. Podemos extrair alguns dos segmentos da fonte índice índice utilizando seqüenciamento com esparsos índice secundário banco de dados.
Sparse seqüenciamento é usado para melhorar o desempenho. Quando algumas ocorrências de índice do segmento de origem não são utilizadas, podemos extrair.
DL/I utiliza um valor da supressão ou repressão rotina ou ambos para determinar se um segmento deve ser indexada.
Se o valor de um campo de seqüência no índice segmento de origem corresponde a um valor da supressão, então sem índice relação é estabelecida.
A repressão rotina é um usuário de programa escrito que avalia o segmento e determina se deve ou não ser indexado.
Quando sparse indexação é utilizado, suas funções são tratadas pelo DL/I. Não precisamos de fazer disposições especiais para o programa de aplicação.
Requisitos DBDGEN
Conforme discutido em módulos anteriores, DBDGEN é usado para criar um DBD. Quando criamos índices secundários, são os dois bancos envolvidos. O DBA precisa criar dois DBDs usando dois DBDGENs para criar uma relação entre o índice banco de dados e um indexado secundário banco de dados.
Requisitos PSBGEN
Depois de criar o índice secundário para um banco de dados, o DBA precisa criar o SPR. PSBGEN para o programa especifica a boa seqüência de processamento para o banco de dados no PROCSEQ parâmetro do PSB macro. Para o PROCSEQ parâmetro, o DBA códigos DBD nome para o índice secundário banco de dados.
