Concurrency vs Parallelism
Both concurrency and parallelism are used in relation to multithreaded programs but there is a lot of confusion about the similarity and difference between them. The big question in this regard: is concurrency parallelism or not? Although both the terms appear quite similar but the answer to the above question is NO, concurrency and parallelism are not same. Now, if they are not same then what is the basic difference between them?
In simple terms, concurrency deals with managing the access to shared state from different threads and on the other side, parallelism deals with utilizing multiple CPUs or its cores to improve the performance of hardware.
Concurrency in Detail
Concurrency is when two tasks overlap in execution. It could be a situation where an application is progressing on more than one task at the same time. We can understand it diagrammatically; multiple tasks are making progress at the same time, as follows −
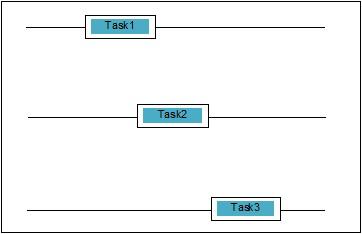
Levels of Concurrency
In this section, we will discuss the three important levels of concurrency in terms of programming −
Low-Level Concurrency
In this level of concurrency, there is explicit use of atomic operations. We cannot use such kind of concurrency for application building, as it is very error-prone and difficult to debug. Even Python does not support such kind of concurrency.
Mid-Level Concurrency
In this concurrency, there is no use of explicit atomic operations. It uses the explicit locks. Python and other programming languages support such kind of concurrency. Mostly application programmers use this concurrency.
High-Level Concurrency
In this concurrency, neither explicit atomic operations nor explicit locks are used. Python has concurrent.futures module to support such kind of concurrency.
Properties of Concurrent Systems
For a program or concurrent system to be correct, some properties must be satisfied by it. Properties related to the termination of system are as follows −
Correctness property
The correctness property means that the program or the system must provide the desired correct answer. To keep it simple, we can say that the system must map the starting program state to final state correctly.
Safety property
The safety property means that the program or the system must remain in a “good” or “safe” state and never does anything “bad”.
Liveness property
This property means that a program or system must “make progress” and it would reach at some desirable state.
Actors of concurrent systems
This is one common property of concurrent system in which there can be multiple processes and threads, which run at the same time to make progress on their own tasks. These processes and threads are called actors of the concurrent system.
Resources of Concurrent Systems
The actors must utilize the resources such as memory, disk, printer etc. in order to perform their tasks.
Certain set of rules
Every concurrent system must possess a set of rules to define the kind of tasks to be performed by the actors and the timing for each. The tasks could be acquiring of locks, memory sharing, modifying the state, etc.
Barriers of Concurrent Systems
While implementing concurrent systems, the programmer must take into consideration the following two important issues, which can be the barriers of concurrent systems −
Sharing of data
An important issue while implementing the concurrent systems is the sharing of data among multiple threads or processes. Actually, the programmer must ensure that locks protect the shared data so that all the accesses to it are serialized and only one thread or process can access the shared data at a time. In case, when multiple threads or processes are all trying to access the same shared data then not all but at least one of them would be blocked and would remain idle. In other words, we can say that we would be able to use only one process or thread at a time when lock is in force. There can be some simple solutions to remove the above-mentioned barriers −
Data Sharing Restriction
The simplest solution is not to share any mutable data. In this case, we need not to use explicit locking and the barrier of concurrency due to mutual data would be solved.
Data Structure Assistance
Many times the concurrent processes need to access the same data at the same time. Another solution, than using of explicit locks, is to use a data structure that supports concurrent access. For example, we can use the queue module, which provides thread-safe queues. We can also use multiprocessing.JoinableQueue classes for multiprocessing-based concurrency.
Immutable Data Transfer
Sometimes, the data structure that we are using, say concurrency queue, is not suitable then we can pass the immutable data without locking it.
Mutable Data Transfer
In continuation of the above solution, suppose if it is required to pass only mutable data, rather than immutable data, then we can pass mutable data that is read only.
Sharing of I/O Resources
Another important issue in implementing concurrent systems is the use of I/O resources by threads or processes. The problem arises when one thread or process is using the I/O for such a long time and other is sitting idle. We can see such kind of barrier while working with an I/O heavy application. It can be understood with the help of an example, the requesting of pages from web browser. It is a heavy application. Here, if the rate at which the data is requested is slower than the rate at which it is consumed then we have I/O barrier in our concurrent system.
The following Python script is for requesting a web page and getting the time our network took to get the requested page −
import urllib.request
import time
ts = time.time()
req = urllib.request.urlopen('http://www.howcodex.com')
pageHtml = req.read()
te = time.time()
print("Page Fetching Time : {} Seconds".format (te-ts))
After executing the above script, we can get the page fetching time as shown below.
Output
Page Fetching Time: 1.0991398811340332 Seconds
We can see that the time to fetch the page is more than one second. Now what if we want to fetch thousands of different web pages, you can understand how much time our network would take.
What is Parallelism?
Parallelism may be defined as the art of splitting the tasks into subtasks that can be processed simultaneously. It is opposite to the concurrency, as discussed above, in which two or more events are happening at the same time. We can understand it diagrammatically; a task is broken into a number of subtasks that can be processed in parallel, as follows −
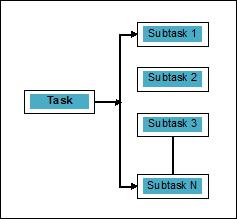
To get more idea about the distinction between concurrency and parallelism, consider the following points −
Concurrent but not parallel
An application can be concurrent but not parallel means that it processes more than one task at the same time but the tasks are not broken down into subtasks.
Parallel but not concurrent
An application can be parallel but not concurrent means that it only works on one task at a time and the tasks broken down into subtasks can be processed in parallel.
Neither parallel nor concurrent
An application can be neither parallel nor concurrent. This means that it works on only one task at a time and the task is never broken into subtasks.
Both parallel and concurrent
An application can be both parallel and concurrent means that it both works on multiple tasks at a time and the task is broken into subtasks for executing them in parallel.
Necessity of Parallelism
We can achieve parallelism by distributing the subtasks among different cores of single CPU or among multiple computers connected within a network.
Consider the following important points to understand why it is necessary to achieve parallelism −
Efficient code execution
With the help of parallelism, we can run our code efficiently. It will save our time because the same code in parts is running in parallel.
Faster than sequential computing
Sequential computing is constrained by physical and practical factors due to which it is not possible to get faster computing results. On the other hand, this issue is solved by parallel computing and gives us faster computing results than sequential computing.
Less execution time
Parallel processing reduces the execution time of program code.
If we talk about real life example of parallelism, the graphics card of our computer is the example that highlights the true power of parallel processing because it has hundreds of individual processing cores that work independently and can do the execution at the same time. Due to this reason, we are able to run high-end applications and games as well.
Understanding of the processors for implementation
We know about concurrency, parallelism and the difference between them but what about the system on which it is to be implemented. It is very necessary to have the understanding of the system, on which we are going to implement, because it gives us the benefit to take informed decision while designing the software. We have the following two kinds of processors −
Single-core processors
Single-core processors are capable of executing one thread at any given time. These processors use context switching to store all the necessary information for a thread at a specific time and then restoring the information later. The context switching mechanism helps us make progress on a number of threads within a given second and it looks as if the system is working on multiple things.
Single-core processors come with many advantages. These processors require less power and there is no complex communication protocol between multiple cores. On the other hand, the speed of single-core processors is limited and it is not suitable for larger applications.
Multi-core processors
Multi-core processors have multiple independent processing units also called cores.
Such processors do not need context switching mechanism as each core contains everything it needs to execute a sequence of stored instructions.
Fetch-Decode-Execute Cycle
The cores of multi-core processors follow a cycle for executing. This cycle is called the Fetch-Decode-Execute cycle. It involves the following steps −
Fetch
This is the first step of cycle, which involves the fetching of instructions from the program memory.
Decode
Recently fetched instructions would be converted to a series of signals that will trigger other parts of the CPU.
Execute
It is the final step in which the fetched and the decoded instructions would be executed. The result of execution will be stored in a CPU register.
One advantage over here is that the execution in multi-core processors are faster than that of single-core processors. It is suitable for larger applications. On the other hand, complex communication protocol between multiple cores is an issue. Multiple cores require more power than single-core processors.
