Legality of Web Scraping
With Python, we can scrape any website or particular elements of a web page but do you have any idea whether it is legal or not? Before scraping any website we must have to know about the legality of web scraping. This chapter will explain the concepts related to legality of web scraping.
Introduction
Generally, if you are going to use the scraped data for personal use, then there may not be any problem. But if you are going to republish that data, then before doing the same you should make download request to the owner or do some background research about policies as well about the data you are going to scrape.
Research Required Prior to Scraping
If you are targeting a website for scraping data from it, we need to understand its scale and structure. Following are some of the files which we need to analyze before starting web scraping.
Analyzing robots.txt
Actually most of the publishers allow programmers to crawl their websites at some extent. In other sense, publishers want specific portions of the websites to be crawled. To define this, websites must put some rules for stating which portions can be crawled and which cannot be. Such rules are defined in a file called robots.txt.
robots.txt is human readable file used to identify the portions of the website that crawlers are allowed as well as not allowed to scrape. There is no standard format of robots.txt file and the publishers of website can do modifications as per their needs. We can check the robots.txt file for a particular website by providing a slash and robots.txt after url of that website. For example, if we want to check it for Google.com, then we need to type https://www.google.com/robots.txt and we will get something as follows −
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..
Some of the most common rules that are defined in a website’s robots.txt file are as follows −
User-agent: BadCrawler
Disallow: /
The above rule means the robots.txt file asks a crawler with BadCrawler user agent not to crawl their website.
User-agent: *
Crawl-delay: 5
Disallow: /trap
The above rule means the robots.txt file delays a crawler for 5 seconds between download requests for all user-agents for avoiding overloading server. The /trap link will try to block malicious crawlers who follow disallowed links. There are many more rules that can be defined by the publisher of the website as per their requirements. Some of them are discussed here −
Analyzing Sitemap files
What you supposed to do if you want to crawl a website for updated information? You will crawl every web page for getting that updated information, but this will increase the server traffic of that particular website. That is why websites provide sitemap files for helping the crawlers to locate updating content without needing to crawl every web page. Sitemap standard is defined at http://www.sitemaps.org/protocol.html.
Content of Sitemap file
The following is the content of sitemap file of https://www.microsoft.com/robots.txt that is discovered in robot.txt file −
Sitemap: https://www.microsoft.com/en-us/explore/msft_sitemap_index.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/licensing/sitemap.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/store/productdetailpages.index.xml
Sitemap: https://www.microsoft.com/en-us/store/locations/store-locationssitemap.xml
The above content shows that the sitemap lists the URLs on website and further allows a webmaster to specify some additional information like last updated date, change of contents, importance of URL with relation to others etc. about each URL.
What is the Size of Website?
Is the size of a website, i.e. the number of web pages of a website affects the way we crawl? Certainly yes. Because if we have less number of web pages to crawl, then the efficiency would not be a serious issue, but suppose if our website has millions of web pages, for example Microsoft.com, then downloading each web page sequentially would take several months and then efficiency would be a serious concern.
Checking Website’s Size
By checking the size of result of Google’s crawler, we can have an estimate of the size of a website. Our result can be filtered by using the keyword site while doing the Google search. For example, estimating the size of https://authoraditiagarwal.com/ is given below −
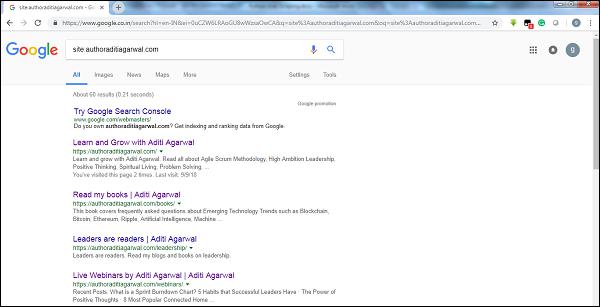
You can see there are around 60 results which mean it is not a big website and crawling would not lead the efficiency issue.
Which technology is used by website?
Another important question is whether the technology used by website affects the way we crawl? Yes, it affects. But how we can check about the technology used by a website? There is a Python library named builtwith with the help of which we can find out about the technology used by a website.
Example
In this example we are going to check the technology used by the website
https://authoraditiagarwal.com with the help of Python library builtwith. But before using this library, we need to install it as follows −
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org/packages/9b/b8/4a320be83bb3c9c1b3ac3f9469a5d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3
Now, with the help of following simple line of codes we can check the technology used by a particular website −
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
Who is the owner of website?
The owner of the website also matters because if the owner is known for blocking the crawlers, then the crawlers must be careful while scraping the data from website. There is a protocol named Whois with the help of which we can find out about the owner of the website.
Example
In this example we are going to check the owner of the website say microsoft.com with the help of Whois. But before using this library, we need to install it as follows −
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org/packages/63/8a/8ed58b8b28b6200ce1cdfe4e4f3bbc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0
Now, with the help of following simple line of codes we can check the technology used by a particular website −
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}
