Hadoop - Configuração do Ambiente
Hadoop é suportada pela plataforma GNU/Linux e seus sabores. Portanto, temos de instalar o sistema operacional Linux para configurar Hadoop meio ambiente. No caso de você ter um sistema operacional diferente de Linux, você pode instalar o Virtualbox software e ter Linux dentro do Virtualbox.
Pré-configuração instalação
Antes de instalar Hadoop para o ambiente Linux, temos de configurar o Linux usando o ssh (Secure Shell). Siga os passos abaixo para configurar o ambiente Linux.
Criando um usuário
No início, é recomendável criar um usuário separado para Hadoop para isolar Hadoop file system do sistema de arquivos Unix. Siga os passos abaixo para criar uma conta de usuário.
- Abra o root usando o comando "su".
- Criar uma conta de usuário da conta root usando o comando "comandos useradd usuário".
- Agora você pode abrir uma conta de usuário existente usando o comando "su usuário".
Abra o Linux terminal e digite os seguintes comandos para criar um usuário.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwd
SSH Configuração e geração de chaves
Configuração SSH é necessário fazer operações diferentes em um cluster, tais como iniciar, parar, distribuídos shell daemon as operações. Para autenticar usuários diferentes do Hadoop, é necessário para fornecer par de chaves pública/privada para o Hadoop user e compartilhá-lo com diferentes usuários.
Os comandos a seguir são usados para gerar um valor de chave par usando o SSH. Copiar as chaves públicas forma id_rsa.pub para authorized_keys e fornecer ao proprietário com permissões de leitura e gravação em arquivo authorized_keys, respectivamente.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
Instalar o Java
O Java é o principal pré-requisito para Hadoop. Primeiro de tudo, você deve verificar a existência de java no seu sistema usando o comando "java -version". A sintaxe do java versão comando é dado abaixo.
$ java -version
Se tudo estiver em ordem, dar-lhe-á a seguinte saída.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Se o java não está instalado no seu sistema, siga os passos abaixo para instalar o java.
Passo 1
Fazer download do java (JDK <latest version> - X64.tar.gz) visitando o link a seguir http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads1880260.html.
Em seguida, o jdk-7u71-linux-x64.tar.gz será baixado no seu sistema.
Passo 2
Geralmente, você irá encontrar o arquivo java baixado na pasta de download. Verifique se ele e extraia o jdk-7u71-linux-x64.gz arquivo usando os seguintes comandos.
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gz
Passo 3
Para tornar java disponível para todos os usuários, você vai ter que ir para o local “/usr/local/”. Open root e digite os seguintes comandos.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exit
Passo 4
Para configurar o caminho e as variáveis JAVA_HOME, adicionar os seguintes comandos para ~/.bashrc file.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/bin
Agora, aplique todas as mudanças no sistema atual.
$ source ~/.bashrc
Passo 5
Use os seguintes comandos para configurar o java alternativas:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jar
Agora verifique se o java -version comando no terminal, conforme explicado acima.
Download Hadoop
Baixe e extraia Hadoop ponto 2.4.1 do Apache software foundation usando os seguintes comandos.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exit
Hadoop Modos de Operação
Uma vez que você tenha baixado Hadoop, você pode operar o Hadoop cluster em um dos três modos suportados:
Local/Modo Autônomo: Depois de baixar o Hadoop em seu sistema, por padrão, ela é configurada de modo independente e pode ser executado como um processo java simples.
Pseudo modo distribuído: é uma simulação distribuída em uma única máquina. Cada daemon, como Hadoop hdfs, fios, MapReduce etc., será executado como um processo java separado. Este modo é útil para o desenvolvimento.
Totalmente distribuída Mode: este modo é totalmente distribuída com um mínimo de duas ou mais máquinas como um cluster. Vamos em frente deste modo em pormenor nos próximos capítulos.
Instalar Hadoop em Modo Autônomo
Aqui vamos discutir a instalação do Hadoop 2.4.1 em modo autônomo.
Não há daemons em execução e tudo é executado em uma única JVM. Modo Autônomo é adequado para executar programas MapReduce durante seu desenvolvimento, pois é fácil de testar e depurar-los.
Criação Hadoop
Você pode definir Hadoop variáveis de ambiente, anexando os seguintes comandos para~/.bashrcarquivo.
export HADOOP_HOME=/usr/local/hadoop
Antes de prosseguir, você precisa se certificar de que o Hadoop está funcionando bem. Basta usar o seguinte comando:
$ hadoop version
Se está tudo bem com a sua configuração, em seguida, você deve ver o seguinte resultado:
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4
Isto significa que o seu modo independente do Hadoop configuração está funcionando bem. Por padrão, Hadoop está configurado para ser executado em um modo não-distribuídos em uma única máquina.
Exemplo
Vamos verificar um exemplo simples do Hadoop. Hadoop instalação fornece o seguinte exemplo MapReduce arquivo jar, que oferece as funcionalidades básicas de MapReduce e pode ser utilizada para o cálculo, como Pi valor, contagens de palavras em uma determinada lista de arquivos, etc.
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar
Vamos ter uma entrada diretório onde vamos empurrar alguns arquivos e nossa exigência é a contagem do número total de palavras em arquivos. Para calcular o número total de palavras, não precisamos escrever nossa MapReduce, desde o arquivo .jar contém a aplicação de contagem de palavras. Você pode tentar outros exemplos utilizando o mesmo arquivo .jar, basta emitir os comandos a seguir para verificar programas funcionais suportadas por MapReduce hadoop, mapreduce-exemplos-2.2.0.jar file.
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar
Passo 1
Criar temporário de conteúdo os ficheiros no directório de entrada. Você pode criar este directório de entrada em qualquer lugar que você gostaria de trabalhar.
$ mkdir input
$ cp $HADOOP_HOME/*.txt input
$ ls -l input
Ele dará os seguintes arquivos no seu directório de entrada:
total 24
-rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt
-rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt
-rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txt
Esses arquivos foram copiados do Hadoop instalação home directory. Para o experimento, você pode ter diferentes e grandes conjuntos de arquivos.
Passo 2
Vamos começar o Hadoop processo para contar o número total de palavras de todos os arquivos disponíveis no directório de entrada, como se segue:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input ouput
Passo 3
Passo-2 irá fazer o processamento necessário e salvar a saída da produção/parte-r00000 arquivo, que você pode verificar através de:
$cat output/*
Ele irá listar todas as palavras juntamente com suas contagens totais disponíveis em todos os arquivos disponíveis no directório de entrada.
"AS 4
"Contribution" 1
"Contributor" 1
"Derivative 1
"Legal 1
"License" 1
"License"); 1
"Licensor" 1
"NOTICE” 1
"Not 1
"Object" 1
"Source” 1
"Work” 1
"You" 1
"Your") 1
"[]" 1
"control" 1
"printed 1
"submitted" 1
(50%) 1
(BIS), 1
(C) 1
(Don't) 1
(ECCN) 1
(INCLUDING 2
(INCLUDING, 2
.............
Instalar Hadoop em Pseudo modo distribuído
Siga os passos abaixo para instalar Hadoop ponto 2.4.1 do pseudo modo distribuído.
1º Passo: Configurando Hadoop
Você pode definir Hadoop variáveis de ambiente, anexando os seguintes comandos para~/.bashrcarquivo.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
Agora, aplique todas as mudanças no sistema atual.
$ source ~/.bashrc
2º Passo: Hadoop Configuração
Você pode encontrar todo o Hadoop arquivos de configuração no local “$HADOOP_HOME/etc/hadoop”. É necessário fazer alterações nos arquivos de configuração de acordo com o Hadoop infra-estrutura.
$ cd $HADOOP_HOME/etc/hadoop
A fim de desenvolver Hadoop programas em java, você tem que reiniciar o java variáveis de ambiente nohadoop-env.sh arquivo substituindo JAVA_HOME valor com a localização do java no seu sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71
A seguir estão a lista de arquivos que você tenha que editar para configurar Hadoop.
Core-site.xml
Ocore-site.xmlfile contém informações como o número da porta usada para Hadoop exemplo, memória alocada para o sistema de arquivos, limite de memória para armazenar os dados, e o tamanho das ler/escrever buffers.
Abrir o core-site.xml e adicionar as seguintes propriedades, entre <configuration>, </configuration> tags.
<configuration>
<property>
<name>fs.default.name </name>
<value> hdfs://localhost:9000 </value>
</property>
</configuration>
hdfs-site.xml
The hdfs-site.xml file contém informações como o valor dos dados de replicação, namenode caminho, e datanode os caminhos dos seus sistemas de arquivos locais. Isso significa que o local onde você deseja armazenar o Hadoop infra-estrutura.
Consideremos os seguintes dados.
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Abra esse arquivo e adicione as seguintes propriedades entre a <configuration> </configuration> tags neste arquivo.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>
Nota: no arquivo acima, todos os valores da propriedade são definidos pelo usuário e você pode fazer alterações de acordo com a infra-estrutura do Hadoop.
yarn-site.xml
Este arquivo é usado para configurar os fios no Hadoop. Abra os fios-site.xml file e adicionar as seguintes propriedades entre a <configuration>, </configuration> tags neste arquivo.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
Este arquivo é usado para especificar quais MapReduce framework que estamos utilizando. Por padrão, Hadoop contém um modelo de yarn-site.xml. Primeiro de tudo, é necessário copiar o arquivo do mapred-site,xml.modelo de mapred-site.xml arquivo xml usando o seguinte comando.
$ cp mapred-site.xml.template mapred-site.xml
Abrir mapred-site.xml arqhivo e adicionar as seguintes propriedades entre a <configuration>, </configuration> tags neste arquivo.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Verificando Hadoop Instalação
Os passos a seguir são utilizados para verificar a Hadoop instalação.
Passo 1: Configuração do nó Nome
Configurar o namenode usando o comando “hdfs namenode -format” como se segue.
$ cd ~
$ hdfs namenode -format
O resultado esperado é a seguinte.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/
2º Passo: Verificar Hadoop dfs
O seguinte comando é utilizado para iniciar o dfs. A execução deste comando irá iniciar o Hadoop file system.
$ start-dfs.sh
O resultado esperado é a seguinte:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
3º Passo: Verificar os fios Script
O seguinte comando é utilizado para iniciar o fio script. A execução deste comando irá iniciar os seus fios daemons.
$ start-yarn.sh
O resultado esperado como segue:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop
2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
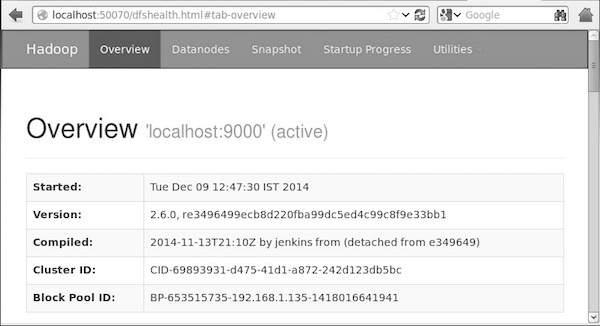
4º Passo: Acessando Hadoop no navegador
O número de porta padrão para acessar Hadoop é 50070. Utilize a seguinte url para obter Hadoop serviços no navegador.
http://localhost:50070/
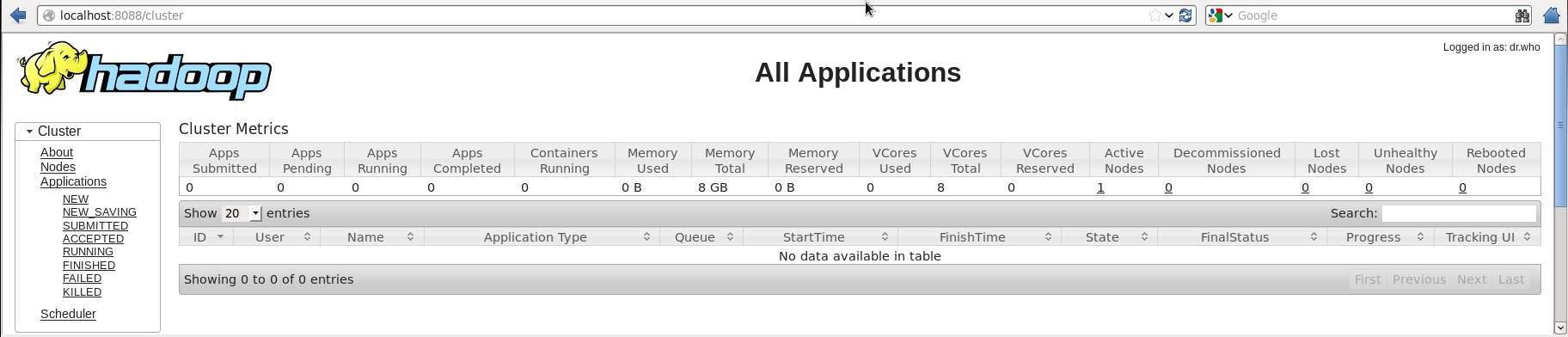
5º Passo: Verifique se todas as aplicações de Cluster
O número de porta padrão para acessar todas as aplicações de cluster é 8088. Utilize a seguinte url para visitar este serviço.
http://localhost:8088/