HBase - Descripción General
Desde 1970, RDBMS es la solución para el almacenamiento de datos y los problemas relacionados con el mantenimiento. Después de la llegada de los grandes datos, las empresas se dieron cuenta de la gran ventaja de la transformación de datos y comenzó optan por soluciones como Hadoop.
Hadoop utiliza sistema de archivos distribuido para almacenar grandes datos y MapReduce a proceso. Hadoop se destaca en el almacenamiento y el procesamiento de grandes cantidades de datos en diversos formatos tales como arbitraria, semi-, o incluso no estructurados.
Limitaciones de Hadoop
Hadoop sólo puede realizar procesamiento por lotes y los datos a los que accederán sólo de una manera secuencial. Eso significa que uno tiene que buscar el conjunto incluso para el más sencillo de los puestos de trabajo.
Un gran conjunto de datos cuando resultados procesados en un gran conjunto de datos, que debe ser también procesa de forma secuencial. En este punto, una nueva solución es necesaria para acceder a cualquier punto de datos en una sola unidad de tiempo (acceso aleatorio).
Hadoop Azar Bases de datos de Access
Aplicaciones como HBase, Cassandra, couchDB, Dynamo y MongoDB son algunas de las bases de datos que almacenan grandes cantidades de datos y acceso a los datos de una forma aleatoria.
HBase ¿Qué es?
HBase es una columna de base de datos orientada al construido en la parte superior de la Hadoop sistema de archivos. Es un proyecto de código abierto y se puede escalar horizontalmente.
HBase es un modelo de datos que es similar a Google la gran tabla diseñada para permitir el rápido acceso aleatorio a enormes cantidades de datos estructurados. Aprovecha la tolerancia a errores de sistema de archivos el Hadoop (HDFS).
Es una parte del ecosistema Hadoop que proporciona al azar tiempo real acceso de lectura/escritura a los datos de la Hadoop Sistema de archivos.
Uno puede almacenar los datos de los HDFS, bien directamente o a través HBase. Consumidor de datos lee y tiene acceso a los datos en forma aleatoria usando HBase HDFS. HBase se sitúa en la parte superior de la Hadoop y Sistema de Archivos proporciona acceso de lectura y escritura.

HBase y HDFS
| HDFS |
HBase |
| HDFS es un sistema de ficheros distribuido adecuado para almacenar archivos de gran tamaño. |
HBase es una base de datos creada en la parte superior de la HDFS. |
| HDFS no admite búsquedas rápidas registro individual. |
HBase proporciona búsquedas rápidas tablas más grandes |
| Proporciona una alta latencia procesamiento por lotes; un concepto de procesamiento por lotes. |
Proporciona acceso de baja latencia a filas de miles de millones de registros (acceso aleatorio). |
| Sólo proporciona acceso secuencial de los datos. |
HBase internamente usa tablas Hash y proporciona acceso aleatorio, y que almacena los datos en archivos indexados HDFS búsquedas más rápido. |
Mecanismo de almacenamiento en HBase
HBase es una columna de base de datos y las tablas en que se ordenan por fila. Esquema de la tabla define solamente la columna las familias, que son los pares de valor clave. Una tabla con varias columnas y cada columna familias familia puede tener cualquier número de columnas. Los valores de columna se almacenan fisicamente en el disco. Cada valor de la celda de la tabla tiene una marca de tiempo. En resumen, en un HBase:
- Tabla es un conjunto de filas.
- Fila es una colección de la columna.
- Columna familia es una colección de columnas.
- Columna es una recopilación de los principales pares de valores.
A continuación se muestra un ejemplo de tabla de esquema HBase.
| Rowide |
Columna |
Columna |
Columna |
Columna |
|
col1 |
col2 |
col3 |
col1 |
col2 |
col3 |
col1 |
col2 |
col3 |
col1 |
col2 |
col3 |
| 1 |
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
|
|
|
|
|
|
|
|
|
|
|
|
Orientado en Columnas y Filas Orientadas
Columna bases de datos son las tablas que almacenan los datos de las secciones de las columnas de datos, en lugar de en las filas de datos. En breve, tendrán columna familias.
| Base Row-Oriented |
Base Column-Oriented |
| Es adecuado para Online Transaction Process (OLTP). |
Es adecuado para Online Analytical Processing (OLAP). |
| Tales bases de datos están diseñados para la pequeña cantidad de filas y columnas. |
Columna bases de datos son diseñados para grandes tablas. |
La siguiente imagen muestra columna familias en una columna de base de datos:
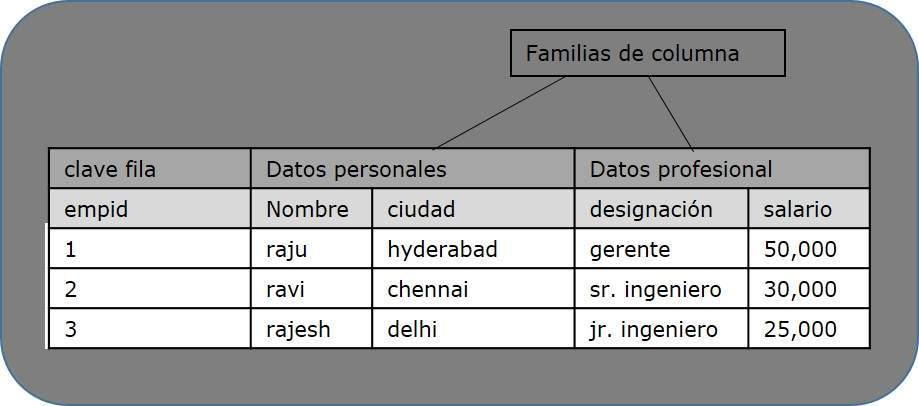
HBase y RDBMS
| HBase |
RDBMS |
| HBase es esquema de menos, no tiene el concepto de esquema columnas fijas; sólo define columna familias. |
Un RDBMS se rige por su esquema, en el que se describe el conjunto de la estructura de las tablas. |
| Está construida de tablas anchas. HBase es escalable horizontalmente. |
Es delgado y construido para pequeñas tablas. Difícil de ampliar. |
| No hay transacciones en HBase. |
RDBMS es transaccional. |
| Ha de datos normalizados. |
Tendrá datos normalizados. |
| Es bueno para semi-estructuradas, así como datos estructurados. |
Es bueno para datos estructurados. |
Características de HBase
- HBase es lineal escalable.
- Ha hecho automático.
- Proporciona lectura coherente y escrituras.
- Se integra con Hadoop, tanto como un origen y un destino.
- Tiene fácil API de java para el cliente.
- Proporciona replicación de datos en clústeres.
Donde Usar HBase
- Apache HBase se utiliza para tener al azar y en tiempo real de acceso de lectura/escritura a los grandes datos.
- Alberga las tablas de gran tamaño en la parte superior de los grupos de hardware de productos básicos.
- Apache HBase es una base de datos relacional basada en Bigtable de Google. Actos de Bigtable de Google File System, del mismo modo Apache HBase trabaja en la parte superior de Hadoop y HDFS.
Las aplicaciones de HBase
- Se usa cuando es necesario escribir aplicaciones pesadas.
- HBase se utiliza cada vez que necesitemos para proporcionar un rápido acceso aleatorio a los datos disponibles.
- Empresas como Facebook, Twitter, Yahoo y Adobe uso HBase internamente.
HBase Historia
| Año |
Evento |
| 2006 Nov |
Google libera el papel de BigTable. |
| 2007 Feb |
HBase prototipo inicial fue creada como Hadoop contribución. |
| 2007 Oct |
La primera utilizable junto con Hadoop HBase 0.15.0 se ha lanzado. |
| 2008 Ene |
HBase se convirtió en el subproyecto de Hadoop. |
| 2008 Oct |
HBase 0.18.1 fue liberado. |
| 2009 Ene |
HBase 0.19.0 fue liberado. |
| 2009 Sept |
HBase 0.20.0 fue liberado. |
| Mayo de 2010 |
HBase convirtió en Apache project de nivel superior. |
