Compilador Diseño - Recuperación de Errores
Un analizador debería ser capaz de detectar y reportar cualquier error en el programa. Es de esperar que cuando se encuentra un error, el analizador debe ser capaz de gestionar y llevar en el análisis sintáctico el resto de la entrada. En su mayoría es de esperarse en el analizador para verificar si hay errores, pero errores se pueden encontrar en las diversas etapas del proceso de compilación. Un programa puede tener los siguientes tipos de errores en las distintas etapas:
Léxico: nombre de una incorrecta identificación
Sintáctico: falta un punto y coma o desequilibrada entre paréntesis
Semántica: incompatible asignación de valor
Lógico: código no accesible, bucle infinito
Hay cuatro errores comunes de las estrategias de recuperación que se pueden implementar en el analizador para lidiar con los errores en el código.
Modo de emergencia
Cuando el analizador encuentra un error en la declaración, se ignora el resto de la declaración no procesando entrada de entrada errónea de delimitador, como punto y coma. Esta es la manera más sencilla de recuperación de errores y, además, impide que el analizador de los bucles infinitos.
Modo Declaración
Cuando el analizador encuentra un error, trata de tomar las medidas correctivas necesarias para que el resto de los insumos de la declaración que el analizador para analizar. Por ejemplo, insertar la falta de un punto y coma, coma con una sustitución punto y coma, etc. Analizador los diseñadores tienen que tener cuidado porque una corrección inadecuada puede llevar a un bucle infinito.
Producciones Error
Algunos de los errores más frecuentes se sabe que el compilador los diseñadores que pueden ocurrir en el código. Además, los diseñadores pueden crear gramática aumentada que se va a utilizar, puesto que las producciones que generan construcciones erróneas cuando estos se encuentran errores.
Corrección Global
El analizador considera que el programa de la mano como un todo y trata de averiguar en qué consiste el programa está destinado a hacer e intenta encontrar una coincidencia más cercana para que esté libre de errores. Cuando una entrada errónea (declaración) X se alimenta, se crea un árbol de análisis sintáctico más cercano algunos libres de error declaración Y. Esto puede permitir que el analizador para hacer cambios mínimos en el código fuente, pero debido a la complejidad (tiempo y espacio) de esta estrategia, no se ha aplicado en la práctica.
Sintaxis Abstracta Árboles
Analizar las representaciones árbol no son fáciles de ser analizado por el compilador, ya que contienen más detalles que realmente se necesita. Tomar las siguientes analizar árbol como un ejemplo:

Si observamos detenidamente, nos encontramos la mayoría de los nodos hoja son uno de los niños a sus nodos principales. Esta información puede ser eliminada antes de dársela a la siguiente fase. Por ocultar información adicional, se puede obtener un árbol como se muestra a continuación:

Árbol abstracto se puede representar de la siguiente forma:
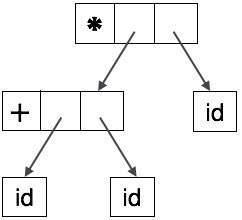
Ast son importantes estructuras de datos en un compilador con menos información innecesaria. Ast son más compactos que analizar un árbol y puede ser fácilmente utilizado por el compilador.
