Software Analyse & Design Tools
Software-Analyse und-Design umfasst alle Aktivitäten, die die Transformation der Anforderungsspezifikation in die Umsetzung zu helfen. Erfordernis Pflichtenheft angeben alle funktionalen und nicht-funktionalen Erwartungen aus die Software. Diese AnforderungsPflichtenheft kommen in Gestalt von Menschen lesbaren und verständlichen Dokumente, auf die ein Computer nichts zu tun hat.
Software-Analyse und Design ist die Zwischenstufe, die für Menschen lesbare Anforderungen in tatsächliche Code verwandelt werden.
Lassen Sie uns sehen wenige Analyse und Design-Tools genutzt von Software-Designer.
Daten Fluss Diagramm
Datenflussdiagramm ist eine graphische Darstellung des Fluss von Daten in einem Informationssystem. Es ist in der Lage, ankommende Datenstrom beschreiben, abgehenden Datenfluss und gespeicherten Daten. Das DFD gabenkein erwähnt, irgendetwas über wie Daten durch das System fließt.
Es ist ein prominenter Unterschied zwischen DFD und Flussdiagramm. Das Flussdiagramm zeigt Ablaufsteuerung in Programm-Module. DFDs zeigen den Datenfluss in dem System auf verschiedenen Ebenen. DFD hat jede Kontrolle oder Zweigelemente enthalten.
Typen von DFD
Datenflussdiagramme sind entweder logische oder physikalische.
Logische DFD - Diese Art von DFD konzentriert sich auf die Systemprozesses und Fluss von Daten in der system. For Beispiel weise in einem Banksoftwaresystem, wie Daten verschoben zwischen verschiedenen Einheiten.
Physikalische DFD - Diese Art von DFD zeigt, wie der Datenfluss tatsächlich im System implementiert. Es ist mehr spezifisch und in der Nähe der Umsetzung.
DFD Komponente
DFD kann darstellen Quelle, Ziel, Speicherung und Fluss von Daten unter Verwendung mit dem folgenden Satz von Komponenten.

Entitäten - Entities sind Quelle und Ziel der Informationsdaten. Entities sind von einem Rechtecke mit ihren jeweiligen Namen vertreten.
Prozess - Aktivitäten und Aktionen genommen auf den Daten werden durch Kreis-oder Rundkantenrechtecke dargestellt.
Datenspeicherung - Es gibt zwei Varianten der Datenspeicherung - es kann entweder vertreten in Form eines Rechtecks mit der Abwesenheit der beide kleinere Seiten oder als Open-Side-Rechteck mit nur einer Seite fehlt.
Daten Fluss - Bewegung der Daten ist durch spitze Pfeile dargestellt. Daten Bewegung wird von der Basis des Pfeil als seine Quelle in Richtung Spitze des Pfeils als Ziel.
Ebenen des DFD
Ebene 0 - Höchsten Abstraktionsebene DFD wird bekannt als Ebene 0 DFD, was zeigen die gesamte Informationssystem als einem ein Diagramm verheimlichen all die zugrunde liegenden details. Level 0 DFDs werden auch als Kontextebene DFDs bekannt.

Ebene 1 - Die Ebene 0 DFD wird in spezifischere, Level 1 DFD gebrochen. Ebene 1 zeigt DFD Grundmodule in dem System und den Fluss von Daten unter den verschiedenen Modulen. Level 1 DFD erwähnt auch grundlegende Prozesse und Quellen von Informationen.

Ebene 2 - Auf dieser Ebene zeigt DFD wie Daten fließt innen den Module genannten in Level 1.
Höher ebene DFDs kann verwandelt in mehr spezifisch ebene DFDs mit tiefere ebene von Verständnis es sei denn die gewünschte ebene von Spezifikationen ist erreicht.
Struktur Charts
Struktur-Charts ist ein Chart aus Datenflussdiagramm abgeleiteten. Es stellt das System in mehr Detail als DFD. Es bricht das gesamte System in niedrigsten Funktionsmodule, beschreibt Funktionen und Unterfunktionen von jedem Module von des Systems in einem größeren Detail als DFD.
Structure chart represents hierarchical structure of modules. At each layer a specific task is performed.
Hier sind die in der Konstruktion der Struktur-Charts verwendeten Symbole -
Module - Es vertritt prozess oder Unterroutine oder Aufgabe. Ein Steuermodulzweige, zu mehr als einen Untermodul. Bibliotheksmodule sind wiederverwendbar und aufrufbaren von jedem Modul.

Bedingung - Es wird von kleinen Diamanten an der Basis des Moduls vertreten. Es zeigt, dass Steuermodul kann irgendeinem der Unter routine basierend auf manche Bedingung selektieren.
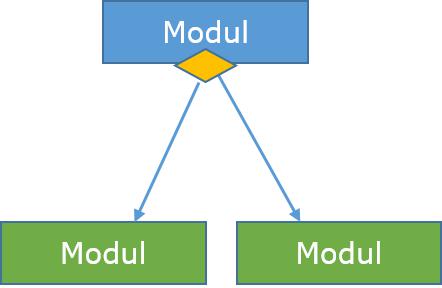
Sprung - Ein Pfeil ist gezeigt zeigen im Inneren des Moduls zu zeigen, dass die Steuerung in der Mitte des Untermodul.

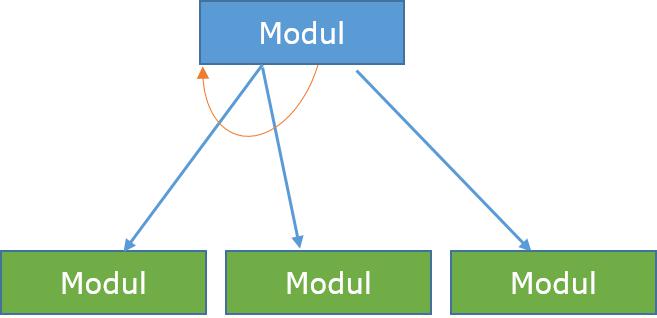
Schleife - Ein gekrümmter Pfeil stellt Schleife in dem Modul. Alle Sub-Module abgedeckt durch schleife Wiederholen Sie Ausführung von Modul.
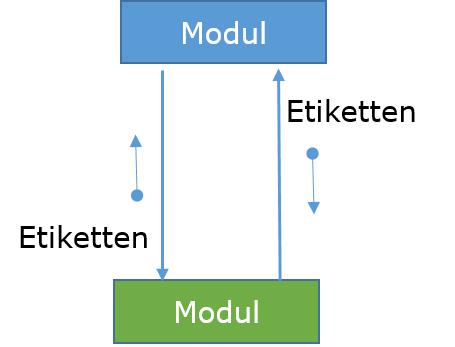
Daten Fluss - Ein gerichteter Pfeil mit leeren Kreis am Ende steht für den Datenfluss.

control Fluss - Ein gerichteter Pfeil mit gefüllten Kreis am Ende steht für Kontrollfluss.
HIPO Diagramm
HIPO (Hierarchical Eingangsprozess Output)-Diagramm ist eine Kombination von zwei organisierten Verfahren, um das System zu analysieren und liefern die Mittel der Dokumentation. HIPO Modell wurde von IBM im Jahr 1970 entwickelt.
HIPO Diagramm stellt die Hierarchie der Module in der Software-System. Analyst verwendet HIPO Diagramm, in Ordnung um High-Level-Ansicht von Systemfunktionen zu erhalten. Es zersetzt Funktionen in Teilfunktionen in hierarchischer Weise. Es zeigt die vom System durchgeführten Funktionen.
HIPO Diagramme sind gut zu Dokumentationszwecken. Ihre grafische Darstellung macht es leichter für Designer und Manager, die bildliche Vorstellung von der Systems Struktur zu erhalten.

Im Gegensatz zu den Börsengang (Eingangsprozess Output)-Diagramm, das den Ablauf der Steuerung und Daten in einem Modul zeigt, HIPO bietet keinen über beliebig Informationen den Datenfluss oder Ablaufsteuerung.

Beispiel
Beide Teile des HIPO Diagramm, Hierarchische Darstellung und IPO-Diagramm sind gebrauchte für Struktur-Design von Software-Programm ebenso gut wie die Dokumentation der gleichen.
Strukturierte Englisch
Die meisten Programmierer sind sich nicht bewusst der großen Bild der Software, so sie auf das, was ihre Manager erzählen , sie tun nur verlassen. Es ist die verantwortung höhere Software-Management um genaue Informationen zu den Programmierern, um genaue noch schnellen Code zu entwickeln.
Andere Formen der Methoden, welche Graphen oder Diagramme verwenden, können sind manchmal von verschiedenen Menschen unterschiedlich interpretiert.
Daher, Analysten und Designern der Software kommen mit Tools wie Strukturierte Englisch. Es ist nichts aber die Beschreibung dessen, was erforderlich ist, um Code und wie es um Code es. Strukturierte Englisch hilft dem Programmierer, fehlerfreiem Code zu schreiben.
Andere Form von Methoden, welche Graphen oder Diagramme verwenden, können sind manchmal von verschiedenen Menschen unterschiedlich interpretiert. Hier sind sowohl Strukturierte Englisch und Pseudo-Code versucht den, zu mildern dass Verständnis Lücke.
Strukturierte Englisch ist es Verwendungen plain English Wörter in strukturierten Programmierparadigma. Es ist nicht die ultimative Code, sondern eine Art der Beschreibung, was ist erforderlich, um Code und wie es um Code es. Im Folgenden einige Tokens der strukturierten Programmierung.
IF-THEN-ELSE,
DO-WHILE-UNTIL
Analyst verwendet die gleichen Variablen und daten Name, welche ist in data Dictionary gespeichert werden, so dass es viel einfachere zu schreiben und zu verstehen, den Code.
Beispiel
Wir nehmen das gleiche Beispiel von Kunden Authentifizierung in der Online-Shopping-Umfeld. Dieses Prozedur, um Kunden zu authentifizieren kann in Structured Englisch geschrieben werden als:
Enter Customer_Name
SEEK Customer_Name in Customer_Name_DB file
IF Customer_Name found THEN
Call procedure USER_PASSWORD_AUTHENTICATE()
ELSE
PRINT error message
Call procedure NEW_CUSTOMER_REQUEST()
ENDIF
Die Code geschrieben in strukturierten Englisch ist mehr wie Tag-zu-Tag gesprochenen Englisch. Es kann nicht direkt als Code der Software implementiert werden. Strukturierte Englisch ist unabhängig von Programmiersprache.
Pseudo-Code
Pseudo-Code wird mehr Nähe zu programmiersprache geschrieben. Es kann sein überlegt als augmented programmiersprache, voll von Kommentaren und Beschreibungen.
Pseudo-Code vermeidet Variablendeklaration, aber sie sind geschrieben mit einige aktuelle Programmiersprache Konstrukten, wie C, Fortran, Pascal usw.
Pseudo-Code enthält mehrProgrammierung Einzelheiten ist als Strukturierte Englisch. Es bietet eine Methode, um die Aufgabe zu ausführen, als wenn ein Computer den Code ausführt.
Beispiel
Programm zu Druck Fibonacci bis zu n Anzahl.
void function Fibonacci
Get value of n;
Set value of a to 1;
Set value of b to 1;
Initialize I to 0
for (i=0; i< n; i++)
{
if a greater than b
{
Increase b by a;
Print b;
}
else if b greater than a
{
increase a by b;
print a;
}
}
Entscheidungstabellen
Eine Entscheidung Tabelle vertritt Bedingungen und jeweiligen Aktionen genommen werden, um sie zu Adress ihnen, in ein strukturierten Tabellenformat.
Es ist ein leistungsfähiges Werkzeug zu debuggen und verhindern Fehler. Es hilft, Gruppe ähnlich Informationen in einer einzigen Tabelle und dann durch Kombinieren von tabellen es Liefert einfach und bequem entscheidungsfindung.
Erstellen von Entscheidungstabelle
Um die Entscheidungstabelle zu erstellen, müssen der Entwickler folgen Grund vier Schritten:
Identifizieren Sie alle möglich Bedingungen sein angesprochen
Bestimmen Sie Aktionen für alle identifizierten Bedingungenetermine actions for all identified conditions
Maximal mögliche Regeln erstellen
Definieren aktion für jede Regel
Entscheidungstabellen sollten durch Endnutzer überprüft werden und können in letzter Zeit sein vereinfachten durch den Wegfall doppelter Regeln und Aktionen.
Beispiel
Nehmen wir ein einfaches Beispiel Tag-zu-Tag Problem mit unserem Internet-Konnektivität. Wir beginnen mit der Identifizierung aller Probleme, dass können entstehen während beginnend die internet und ihre jeweiligen mögliche Lösungen .
Wir listen alle mögliche Probleme unter der spalte Bedingungen und prospektiv Handlungen unter der spalte Aktionen.
|
Bedingungen / Aktionen |
Reglement |
| Bedingungen |
Zeigt Verbunden |
N |
N |
N |
N |
J |
J |
J |
J |
| Ping ist Arbeit |
N |
N |
J |
J |
N |
N |
J |
J |
| Öffnet Webseite |
J |
N |
J |
N |
J |
N |
J |
N |
| Aktionen |
Überprüfen Sie Netzwerkkabel |
X |
|
|
|
|
|
|
|
| Überprüfen Sie Internet-Router |
X |
|
|
|
X |
X |
X |
|
| Neustart Web-Browser |
|
|
|
|
|
|
X |
|
| Kontakt Service-Provider |
|
X |
X |
X |
X |
X |
X |
|
| Tun keine Aktion |
|
|
|
|
|
|
|
|
Tabelle: Entscheidung Tabelle - In-house Internet Fehlerbehebung
Entity-Relationship-Modell
Entity-Relationship-Modell ist eine Art von Datenbank-Modell basiert auf dem Begriff der realen Welt Entitäten und Beziehungen unter ihnen. Wir können realen WeltSzenario onto ER Datenbank-Modell. ER-Modell erstellt eine Reihe von Organisationen, die mit ihren Attributen, eine Reihe von Einschränkungen und die Beziehung unter ihnen.
ER-Modell ist am besten für die begrifflich Entwurf der datenbank verwendet wird. ER-Modell kann wie folgt dargestellt werden:

Entity - Ein Unternehmen in ER-Modell ist eine echte Welt sein, welche einige Eigenschaften namens hat Attribute. Jedes Attribut wird durch seinen entsprechenden Satz von Werten definiert, genannt Domain.
Betrachten Sie zum Beispiel eine Schule Datenbank. Hier ein Schüler ist eine Entität. Student hat verschiedene Attribute wie Name, ID, Alter und Klasse etc.
Beziehung - Die logische Zuordnung unter Entitäten ist Genannt Beziehung. Beziehungen abgebildet werden mit Einträge auf verschiedene Weise. Mapping Kardinalitäten definieren die Anzahl auf Vereinigungs zwischen zwei Entitäten.
Mapping Kardinalitäten
- ein zu ein
- ein zu viele
- viele zu ein
- viele zu viele
Datenlexikon
Datenwörterbuch ist die zentralisierte Sammlung von Informationen über Daten. Es speichert Bedeutung und Herkunft von Daten, seine Beziehung mit anderen Daten, Datenformat für die Nutzungs etc. Daten Wörterbuch hat rigorosDefinitionen aller Namen, um Benutzer und Software-Designer zu erleichtern.
Datenwörterbuch wird oft als Meta-Daten (Daten über Daten) Repository verwiesen. Es wird zusammen mit DFD (Datenflussdiagramm) Modell der Software-Programm erstellt und wird voraussichtlich aktualisiert, wann auch immer DFD ist geändert oder aktualisiert.
Forderung der Datenlexikon
Die Daten ist verwiesen via Datenwörterbuch, während der Entwerfen und Umsetzung Software Datenwörterbuch entfernt beliebig Chancen von Mehrdeutigkeit. Es hilft Haltung Arbeit von Programmierern und Designern synchronisiert während unter Verwendung gleichen Objektreferenz überall im Programm.
Datenwörterbuch bietet eine Möglichkeit der Dokumentation für die komplette Datenbanksystem an einem Ort. Validierung des DFD wird unter Verwendung Data Dictionary durchgeführt.
Inhaltsverzeichnis
Datenwörterbuch sollte enthalten informationen etwa die folgenden.
- Daten Fluss
- Daten Struktur
- Daten Elemente
- Daten speichert
- Daten Verarbeitung
Datenfluss ist beschrieben durch Mittel von DFDs als studierte früher und Vertreten in Algebraische form als beschrieben.
| = |
Composed of |
| {} |
Repetition |
| () |
Optional |
| + |
And |
| [ / ] |
Or |
Beispiel
Adress = Haus Nr + (Straße / Bereich) + Stadt + Zustand
Kurs-ID = Kursnummer + Kursname + Kursstufe + KursGrade
Daten Elemente
Datenelemente besteht aus Name und Beschreibungen von Daten und Kontrolle Einzelteile, interner oder externer Datenspeichern usw. mit den folgenden Details:
- primären Namen
- Zweiter Name (Alias)
- Use-Case (Wie und wo zu verwenden)
- Inhalt Beschreibung (Notation etc.)
- Zusatz - Informationen (voreingestellte Werte, Einschränkungen etc.)
Daten speichert
Er speichert die Informationen von wo dem die Daten tritt in das System und existiert aus dem system heraus. Auf den Datenspeicher können gehören -
- Dateien
- Interne zu Software.
- Externe zu Software, sondern auf der gleichen Maschine.
- Externe zu Software und System, gelegen auf anders Maschine.
- Tabellen
- Namenskonvention
- Indizierung Eigenschaft
Daten Verarbeitung
Es gibt zwei Arten der Daten verarbeitung:
