HBase - Überblick
Seit 1970, ist RDBMS die Lösung für die Datenspeicherung und Wartungsverwandtproblemen. Nach dem Aufkommen von groß Daten, erkannte Unternehmen den Nutzen der Verarbeitung von groß Daten und begann optieren für Lösungen mögen Hadoop.
Hadoop verwendet verteiltes Dateisystem für die Speicherung von großen Daten und Karte reduzieren, sie zu verarbeiten. Hadoop sich hervortun in sich die Speicherung und Verarbeitung von großen Daten von verschiedenen Formaten wie willkürlich, halb-, oder sogar unstrukturierte.
Einschränkungen von Hadoop
Hadoop kann Stapelverarbeitung durchzuführen, und die Daten werden sein abgerufen nur in einer sequentiellen Art. Das heißt, ein hat zu gesamten Datensatz sogar für die einfachsten Arbeitsplätze zu finden.
Eine große DatenSetz wann Verarbeitet Ergebnisse in einem anderen großen DatenSetz, welche sollen auch sein Verarbeitet sequenziell. An diesem Punkt wird eine neue Lösung benötigt,zu Zugriff um jeden Punkt der Daten in einer einzigen Zeiteinheit (wahlfreier Zugriff).
Hadoop wahlfreier Zugriff Datenbanken
Anwendungen wie HBase, Cassandra, CouchDB, Dynamo und MongoDB sind einige der Datenbanken, dass große Datenmengen zu speichern und zugriff auf die Daten in einer zufälligen Weise.
Was ist HBase?
HBase ist eine verteilte spaltenorientierte Datenbank auf Spitze der Hadoop Dateisystem aufgebaut. Es ist ein Open-Source-Projekt und ist horizontal skalierbar ist.
HBase ist ein Datenmodell, dass ist ähnlich wie die Google-groß Tisch entwickelt, um eine schnelle wahlfreien Zugriff auf riesige Mengen an strukturierten Daten zu liefern. Es Hebelkräfte die Fehlertoleranz stellt durch die Hadoop File System (HDFS).
Es ist ein Teil der Hadoop-Ökosystem, dass stellt zufalls echtzeit Lesen / Schreibzugriff auf Daten in der Hadoop-Dateisystem.
Ein kann die Daten in HDFS entweder direkt oder über HBase speichern. Daten Verbraucher liest / auf die Daten zugreift in HDFS zufällig verwendung HBase. HBase sitzt oben auf dem Hadoop-Dateisystem und bietet Lese- und Schreibzugriff.

HBase und HDFS
| HDFS |
HBase |
| HDFS ist ein verteiltes Dateisystem geeignet für die Speicherung von großen Dateien. |
HBase ist eine Datenbank, auf der Oberseite des HDFS gebaut. |
| HDFS bietet keine Unterstützung für schnelle einzelnen Datensatz Lookups. |
HBase bietet schnelle Lookups für größere Tabellen. |
| Sie stellt hohe Latenz Batch-Verarbeitung; kein Konzept der Stapelverarbeitung. |
Sie stellt geringe Latenz Zugriff auf einzelne Zeilen aus Milliarden von Datensätzen (Zufalls Zugang). |
| Sie stellt nur sequentiellen Zugriff von Daten. |
HBase intern verwendet Hash-Tabellen und stellt Zufallszugriff, und es speichert die Daten in Indiziert HDFS Dateien für schnellere Lookups. |
Speichermechanismus in HBase
HBase ist ein spaltenorientierte Datenbank und die Tische in es sind sortiert durch Reihe. Das Tabellenschema definiert nur Spalten Familien, die die Schlüssel-Wert-Paare sind. Eine Tabelle mehrere Spalten Familien und jede Spalte Familie kann eine beliebige Anzahl von Spalten haben. Anschließend Spaltenwerte werden zusammenhängend auf der Platte gespeichert. Jede Zelle Wert des Tabelle einen Zeitstempel. Kurz gesagt, in einem HBase:
- Tabelle ist eine Sammlung von Zeilen.
- Reihe ist eine Sammlung von Spalten Familien.
- Spalte Familie ist eine Sammlung von Spalten.
- Spalte ist eine Sammlung von Schlüssel-Wert-Paaren.
Da unten ist ein Beispiel Schema der Tabelle in HBase.
| Rowide |
Spalte Familie |
Spalte Familie |
Spalte Familie |
Spalte Familie |
|
col1 |
col2 |
col3 |
col1 |
col2 |
col3 |
col1 |
col2 |
col3 |
col1 |
col2 |
col3 |
| 1 |
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
|
|
|
|
|
|
|
|
|
|
|
|
Spalte Orientiert und Reihen Orientiert
spaltenorientierte Datenbanken sind diejenigen, die Datentabellen zu speichern, wie Abschnitte der Spalten von Daten, und nicht als reihen von Daten. Kurz,sie wird haben Spalte Familien.
| Reihen orientierte Datenbank |
Spalte-orientierte Datenbank |
| Es ist geeignet für Online-Transaktionsprozess (OLTP). |
Es ist geeignet für Online analytischenVerarbeitung(OLAP). |
| Solche Datenbanken sind entworfen für kleine Anzahl von Zeilen und Spalten. |
spaltenorientierte Datenbanken sind für große Tabellen entwickelt. |
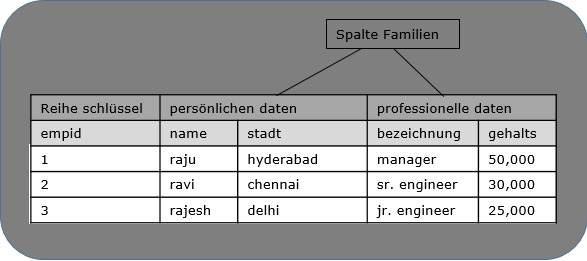
Die folgende Abbildung zeigt Spalte Familien in einer spaltenorientierten Datenbank:
HBase und RDBMS
| HBase |
RDBMS |
| HBase ist schema weniger, es muss nicht das Konzept der festen Spalten-Schema; definiert nur Spalten Familien. |
Ein RDBMS wird durch seine Schema, welche die gesamte Struktur der Tabellen beschrieben geregelt. |
| Es ist für breite Tabellen aufgebaut. HBase ist horizontal skalierbar. |
Es ist dünn und für kleine Tische aufgebaut. Schwer zu skalieren. |
| keine Transaktionen gibt es in HBase. |
RDBMS ist transaktional. |
| Es hat de-normalisierten Daten. |
Es wird normalisierte Daten haben. |
| Es ist gut für halb strukturiert ebenso gut wie strukturierte Daten. |
Es ist gut für strukturierte Daten. |
Eigenschaften von HBase
- HBase ist linear skalierbar.
- Es hat automatische Ausfall Unterstützung.
- Sie stellt konsistente Lese und schreibt.
- Es integriert sich mit Hadoop, sowohl als Quelle und einem Ziel.
- Es hat einfache Java API für Client.
- Sie bietet Datenreplikation über Cluster.
Wo zu Verwenden HBase?
- Apache HBase wird verwendet, um zufällige, Echtzeit-Lese / Schreib-Zugriff auf groß Daten zu haben.
- Es beherbergt sehr große Tabellen auf top von Cluster von Standardhardware.
- Apache HBase ist eine nicht-relationale Datenbank modelliert, nachdem die Google-Bigtable. Bigtable wirkt oben auf Google datei System, ebenfalls Apache HBase arbeitet oben auf Hadoop und HDFS.
Anwendungen von HBase
- Es wird verwendet, wenn es notwendig ist, um schwere Anwendungen zu schreiben.
- HBase wird verwendet, wenn wir brauchen, um schnell wahlfreien Zugriff auf verfügbare Daten zu liefern.
- Unternehmen wie Facebook, Twitter, Yahoo und Adobe verwenden HBase intern.
HBase Geschichte
| Jahr |
Ereignis |
| Nov 2006 |
Google veröffentlicht das Papier auf BigTable. |
| Feb 2007 |
Initiale HBase Prototyp wurde als Hadoop Beitrag erstellt. |
| Okt 2007 |
Die erste nutzbare HBase entlang mit Hadoop 0.15.0 wurde Freigegeben. |
| Jan 2008 |
HBase Wurde das Unterprojekt von Hadoop. |
| Okt 2008 |
HBase 0.18.1 veröffentlicht wurde. |
| Jan 2009 |
HBase 0.19.0 veröffentlicht wurde. |
| Sept 2009 |
HBase 0.20.0 veröffentlicht wurde. |
| Mai 2010 |
HBase wurde Apache Top-Ebene-Projekt. |
