Hadoop - Kartereduzieren
Karte Reduzieren ist ein Rahmen unter Verwendung welche wir kann schreiben Anwendungen riesige Datenmengen zu verarbeiten parallel, auf große Cluster von Standardhardware in zuverlässiger Weise.
Was ist Kartereduzieren?
Kartereduzieren ist ein VerarbeitungsTechnik und ein Programm-Modell für verteiltes Rechnen auf Basis von Java. Die Kartereduzieren Algorithmus enthält zwei wichtige Aufgaben, nämlich Karte und reduzieren. Karte nimmt einen Satz von Daten und wandelt sie in andere Satz von Daten, bei denen einzelne Elemente sind gebrochen unten in Tupeln (Schlüssel / Wert-Paaren). Zweitens verringern Aufgabe, die die Ausgabe von einer Karte nimmt als Eingang und kombiniert diese DatenTupeln in eine kleinere Menge von Tupeln. Wie die Sequenz von Namen Kartereduzieren impliziert die Reduzieren Aufgabe wird ist immer durchgeführt nach die karte Job.
Der große Vorteil Kartereduzieren ist, dass es einfach ist, die Datenverarbeitung über mehrere Rechenknoten zu skalieren. Unter dem Kartereduzieren Modell die Datenverarbeitung Primitive werden genannt Mappern und Reduzierungen. Zerlegen eines Datenverarbeitungsanwendung in Mappern und Reduzierungen ist manchmal nicht trivialen. Aber, sobald wir schreiben eine Anwendung in der Kartereduzieren Form, die Skalierung der Anwendung auf über Hunderte, Tausende oder sogar Zehntausende von Maschinen in einem Cluster ausgeführt ist lediglich eine Konfigurationsänderung. Diese einfache Skalierbarkeit, was viele Programmierer angezogen, um die Kartereduzieren Modell verwenden.
Der Algorithmus
Im Allgemeinen Kartereduzieren Paradigma basiert auf dem Senden der Computer an zu wo die Daten befinden residieren!
Kartereduzieren Programm ausführt in drei Stufen, nämlich karte Bühne, Shuffle Bühne und reduzieren Bühne.
Karte Bühne : Die Karte oder Mapper hat die Aufgabe, die Eingangsdaten zu verarbeiten. Im Allgemeinen werden die Eingangsdaten in Form von Dateien oder Verzeichnisse und wird gespeichert im Hadoop Dateisystem (HDFS). Die Eingabedatei ist mit dem Mapper Funktion Zeile für Zeile übergeben. Der Mapper verarbeitet die Daten und erstellt mehrere kleine Brocken von Daten.
Reduzieren Bühne : Diese Bühne ist die Kombination aus dem Shuffle Bühne und die Reduzieren Bühne. Die Reducer hat die Aufgabe, die Daten, die von dem Mapper kommt zu verarbeiten. Nach der Verarbeitung, erzeugt er einen neuen Satz von Ausgangs, die im HDFS gespeichert wird.
Während eines Kartereduzieren Job, Hadoop schickt die Karte und Reduzieren Aufgaben zu die angemessen Server im Cluster.
Das Rahmen verwaltet alle Details der Daten VorbeigehenAufgaben wie die Ausstellung von Aufgaben, die Verifizieren der Aufgabenerledigung und Kopieren von Daten Umgebung von der Cluster zwischen den Knoten.
Die meisten der Rechnen findet am Knoten mit Daten auf lokalen Festplatten, dass reduzieren Netzwerkverkehr.
Nach Abschluss von gestellten Aufgaben, die Cluster sammelt sich und reduziert die Daten auf ein entsprechendes Ergebnis, und sendet sie zurück an die Hadoop-Server.
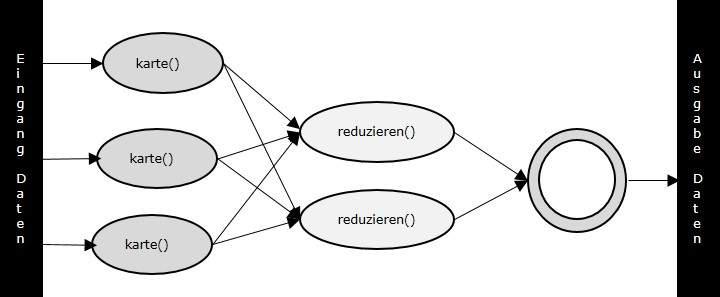
Ein- und Ausgänge (Java Perspektive)
Die Kartereduzieren Rahmen arbeitet auf <Schlüssel, Wert> Paaren, das heißt, der Rahmen Ansichten die Eingabe an den Job als eine Satz von <Schlüssel, Wert> Paare und produziert einen Satz von <Schlüssel, Wert> Paare wie Ausgang von die Jobs, Denkbar von unterschiedlichen Typs.
Der Schlüssel und die Wertklassen sollte in serialisierten Weise durch den Rahmen zu sein, und daher müssen die Writable-Schnittstelle implementieren. Darüber hinaus haben die Schlüssel Klassen, das Writable-Interface Comparable implementieren, um zu erleichtern Sortierung nach Rahmen. Ein- und Ausgabetypen eines Kartereduzieren Job: (Eingabe) <k1, v1> -> map -> <k2, v2>-> reduzieren -> <k3, v3>(Ausgabe).
|
Ein- |
Ausgänge |
| Karte |
<k1, v1> |
Liste (<k2, v2>) |
| reduzieren |
<k2, Liste(v2)> |
Liste (<k3, v3>) |
Terminologie
Nutzlast - Anwendungen implementieren die Karte und die Reduzierung der Funktionen und bilden den Kern der Job.
Mapper - Mapper ordnet die Eingabe Schlüssel / Wert-Paaren auf eine Satz von Zwischen Schlüssel / Wert-Paar.
benannten Knoten - Knoten, die die Hadoop Distributed File System (HDFS) verwaltet.
Datenknoten - Knoten, wo die Daten ist präsentiert im Voraus bevor irgendwelche der Verarbeitung stattfindet.
Master-Knoten - knoten wo Jobtracker läuft und welche Job-Anforderungen von Clients akzeptiert.
Sklave Knoten - Knoten, wo Karte und reduzieren Programm läuft.
JobTracker - Zeitpläne Jobs und Bahnen die assign Arbeitsplätze, um den Task-Tracker.
Aufgabe Tracker - Bahnen die Aufgabe und Berichte Status zu Jobtracker.
Stellenangebote - Ein Programm ist Ausführung von Mapper und Reducer über einem Datensatz.
Task - Ein Ausführung von Mapper oder Reducer auf einer Scheibe von Daten.
Task Versuch - Ein besonderes Beispiel für den Versuch, eine Aufgabe auf einem Sklave Knoten ausführen.
Beispielszenario
Da unten sind die Daten über den Stromverbrauch einer Organisation. Es enthält die monatlichen Stromverbrauch und die im Jahresdurchschnitt für verschiedene Jahre.
|
Jan |
Feb |
Mär |
Apr |
Mai |
Jun |
Jul |
Aug |
Sep |
Okt |
Nov |
Dez |
Avg |
| 1979 |
23 |
23 |
2 |
43 |
24 |
25 |
26 |
26 |
26 |
26 |
25 |
26 |
25 |
| 1980 |
26 |
27 |
28 |
28 |
28 |
30 |
31 |
31 |
31 |
30 |
30 |
30 |
29 |
| 1981 |
31 |
32 |
32 |
32 |
33 |
34 |
35 |
36 |
36 |
34 |
34 |
34 |
34 |
| 1984 |
39 |
38 |
39 |
39 |
39 |
41 |
42 |
43 |
40 |
39 |
38 |
38 |
40 |
| 1985 |
38 |
39 |
39 |
39 |
39 |
41 |
41 |
41 |
00 |
40 |
39 |
39 |
45 |
Wenn die oben genannten Daten als Eingabe gegeben, haben wir, um Anwendungen zu schreiben, sie zu verarbeiten und zu Ergebnissen führen wie die Suche nach dem Jahr der maximalen Nutzung, Jahr der Mindestumsatz, und so weiter. Dies ist ein Freilos für die Programmierer mit begrenzter Anzahl von Datensätzen. Sie werden einfach schreiben die Logik, um die gewünschte Ausgabe zu erzeugen, und die Daten an die Anwendung geschrieben.
Aber, denken Sie an die Daten repräsentiert die den Stromverbrauch aller groß angelegte Industrie von einem bestimmten Zustand, seit ihrer Formation.
Wenn wir schreiben um Anwendungen zu prozess wie Massendaten
- Sie werden viel Zeit nehmen, um ausführen.
- dort wird ein starker Netzwerkverkehr, wenn wir Daten zu bewegen von der Quelle zum Netzwerk-Server und so weiter.
Um diese Probleme zu lösen, haben wir die Kartereduzieren Rahmen.
Eingabedaten
Die oben genannten Daten ist als sample.txt gespeichert und als Input gegeben. Die Eingabedatei sieht wie unten dargestellt.
1979 23 23 2 43 24 25 26 26 26 26 25 26 25
1980 26 27 28 28 28 30 31 31 31 30 30 30 29
1981 31 32 32 32 33 34 35 36 36 34 34 34 34
1984 39 38 39 39 39 41 42 43 40 39 38 38 40
1985 38 39 39 39 39 41 41 41 00 40 39 39 45
Beispielprogramm
Da unten ist das Programm zu Beispieldaten verwendung Kartereduzieren Rahmen.
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits
{
//Mapper class
public static class E_EMapper extends KartereduzierenBase implements
Mapper<LongWritable ,/*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException
{
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens())
{
lasttoken=s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends KartereduzierenBase implements
Reducer< Text, IntWritable, Text, IntWritable >
{
//Reduce function
public void reduce( Text key, Iterator <IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
int maxavg=30;
int val=Integer.MIN_VALUE;
while (values.hasNext())
{
if((val=values.next().get())>maxavg)
{
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception
{
JobConf conf = new JobConf(Eleunits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
Speichern Sie das obige Programm wie ProcessUnits.java. Die Zusammenstellung und Ausführung des Programms wird nachstehend erläutert.
Zusammenstellung und Durchführung von Prozess-Units-Programm.
Nehmen wir an, die wir in das Home-Verzeichnis eines Hadoop User (zB / home / Hadoop) sind.
Führen Sie die unten angegebenen Schritte, um zu kompilieren und führen Sie das obige Programm.
Schritt 1
Der folgende Befehl ist zu schaffen ein Verzeichnis um die kompilierten Java-Klassen zu speichern.
$ mkdir units
Schritt 2
herunterladen Hadoop-core-1.2.1.jar, die verwendet wird, um zu kompilieren und führen Sie den Kartereduzieren Programm. Besuchen Sie den folgenden Link http://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core/1.2.1 zu herunterladen das Glas . Nehmen wir an, die heruntergeladenen Ordner ist /home/hadoop/.
Schritt 3
Die folgenden Befehle werden verwendet für Zusammenstellung der ProcessUnits.java Programm und die Schaffung eines jar für das Programm .
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java
$ jar -cvf units.jar -C units/ .
Schritt 4
Mit dem folgenden Befehl wird verwendet, um eine Eingangsverzeichnis in HDFS erstellen.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
Schritt 5
Mit dem folgenden Befehl wird verwendet, um die Eingabedatei mit dem Namen sample.txt im Eingangsverzeichnis des HDFS kopieren.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir
Schritt 6
Mit dem folgenden Befehl ist verwendet zu verifizieren die Dateien in das Eingabeverzeichnis .
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
Schritt 7
Mit dem folgenden Befehl wird verwendet zu ausgeführt die Eleunit_max Anwendung, indem Einnahme die Eingabedateien aus dem Eingangsverzeichnis .
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
Warten Sie eine Weile, bis die Datei ausgeführt wird. Nach der Ausführung, wie unten gezeigt, wird die Ausgabe enthalten der Anzahl der Eingangsspaltet , die Anzahl der Map Aufgaben die Anzahl der Aufgaben Minderer etc.
INFO Kartereduzieren.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO Kartereduzieren.Job: Counters: 49
File System Counters
FILE: Number of bytes read=61
FILE: Number of bytes written=279400
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=546
HDFS: Number of bytes written=40
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2 Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=146137
Total time spent by all reduces in occupied slots (ms)=441
Total time spent by all map tasks (ms)=14613
Total time spent by all reduce tasks (ms)=44120
Total vcore-seconds taken by all map tasks=146137
Total vcore-seconds taken by all reduce tasks=44120
Total megabyte-seconds taken by all map tasks=149644288
Total megabyte-seconds taken by all reduce tasks=45178880
Map-Reduce Framework
Map input records=5
Map output records=5
Map output bytes=45
Map output materialized bytes=67
Input split bytes=208
Combine input records=5
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=6
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=948
CPU time spent (ms)=5160
Physical memory (bytes) snapshot=47749120
Virtual memory (bytes) snapshot=2899349504
Total committed heap usage (bytes)=277684224
File Output Format Counters
Bytes Written=40
Schritt 8
Mit dem folgenden Befehl wird verwendet, um die Resultante Dateien im Ausgabeordner zu überprüfen.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
Schritt 9
Mit dem folgenden Befehl wird verwendet, um die Ausgabe in Part-00000 Datei zu sehen. Diese Datei wird von HDFS erzeugt.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
Unten ist der Ausgang generiert von der Kartereduzieren Programm .
1981 34
1984 40
1985 45
Schritt 10
Mit dem folgenden Befehl wird für die Analyse verwendet, um die Ausgabe-Ordner von HDFS in das lokale Dateisystem kopieren.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoop
Wichtige Kommandos
Alle Hadoop Befehle werden von der $ HADOOP_HOME / bin / Hadoop Befehl aufgerufen. Das Ausführen des Hadoop-Skript ohne Argumente gibt die Beschreibung für alle Befehle.
Verwendung : Hadoop [--config Confdir] COMMAND
In der folgenden Tabelle sind die verfügbaren Optionen und deren Beschreibung.
| Optionen |
Beschreibung |
| namenode -format |
Formatiert die DFS-Dateisystem. |
| secondarynamenode |
Führt den DFS Sekundär namenode. |
| namenode |
Führt den DFS namenode. |
| datanode |
Führt eine DFS DataNode. |
| dfsadmin |
Führt eine DFS-Admin-Client. |
| mradmin |
Läuft ein Map-Reduce Admin-Client. |
| fsck |
führt ein Dienstprogramm aus DFS-Dateisystem überprüfen. |
| fs |
Läuft ein generisches Dateisystem Benutzer-Client. |
| balancer |
Führt einen Cluster Ausgleich Programm. |
| oiv |
Wendet die offline fsimage Betrachter zu einer fsimage. |
| fetchdt |
Holt einen Delegationstoken vom NameNode. |
| jobtracker |
Führt den Kartereduzieren Job Tracker-Knoten. |
| pipes |
Führt eine Pipes Job. |
| tasktracker |
Führt eine Kartereduzieren Aufgabe Tracker-Knoten. |
| historyserver |
Läuft Job-Historie-Server als Standalone-Daemon. |
| Job |
manipuliert die Kartereduzieren Arbeitsplätze. |
| Queue |
Ruft Informationen über JobQueues. |
| version |
Drucke die Version. |
| jar <jar> |
Führt eine JAR-Datei. |
| distcp <srcurl> <desturl> |
Kopiert Dateien und Verzeichnisse rekursiv. |
| distcp2 <srcurl> <desturl> |
DistCp version 2. |
| archivieren Name NAME -p |
Erstellt eine Hadoop-Archiv. |
| <geordneten Pfad> <src>* <dest> |
|
| Klassenpfad |
Druckt den Klassenpfad benötigt, um die Hadoop-Glas erhalten und die erforderlichen Bibliotheken. |
| daemonlog |
bekommen/Satz der Log-Level für jeden Dämon |
Wie man mit Kartereduzieren Jobs interagieren
Verwendung: hadoop job [GENERIC_OPTIONS]
Im Folgenden werden die generischen Optionen in einem Hadoop Job verfügbar.
| GENERIC_OPTIONS |
Beschreibung |
| -submit <job-file> |
übergibt den Job. |
| status <job-id> |
Druckt die Karte und reduzieren Prozentsatz der Fertigstellung und alle Auftragszähler. |
| Zähler <job-id> <group-name> <countername> |
Druckt den Zählerwert. |
| -töten <job-id> |
Tötet den Job. |
| -Geschehen <job-id> <fromevent-#> <#-of-Geschehen> |
Druckt die Ereignisse "Details von Jobtracker für den angegebenen Bereich erhalten. |
| -history [all] <jobOutputDir> - history < jobOutputDir> |
Druckt Auftragsdetails, gescheitert und getötet Tipp Details. Mehr Details über den Job, wie erfolgreich Aufgaben und Aufgaben Versuche für jede Aufgabe gemacht durch Angabe des [alles] Option betrachtet werden. |
| -list[all] |
Zeigt alle Aufträge. -list zeigt nur Jobs, die noch zu vollenden. |
| -töten-Aufgabe <Aufgabe-id> |
Tötet die Aufgabe. Killed Aufgaben nicht gegen Fehlversuche gezählt. |
| -scheitern-Aufgabe <Aufgabe-id> |
scheitert die Aufgabe. Fehlgeschlagene sind Aufgaben gezählt gegen |
|
Fehlversuche. |
| Satz-Priorität <job-id> <Priorität> |
Ändert die Priorität des Auftrags. Erlaubt Prioritätswerte sind VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW |
Um den Status der Arbeit zu sehen
$ $HADOOP_HOME/bin/hadoop job -status <JOB-ID>
e.g.
$ $HADOOP_HOME/bin/hadoop job -status job_201310191043_0004
Um die Geschichte der Job-Ausgabe-dir sehen
$ $HADOOP_HOME/bin/hadoop job -history <DIR-NAME>
e.g.
$ $HADOOP_HOME/bin/hadoop job -history /user/expert/output
Um den Job zu töten
$ $HADOOP_HOME/bin/hadoop job -kill <JOB-ID>
e.g.
$ $HADOOP_HOME/bin/hadoop job -kill job_201310191043_0004
