Übersetzerbau - Fehler Wiederherstellung
Ein Parser sollten in der Lage zu erkennen und melden Sie den Fehler im Programm. Es wird erwartet, dass, wenn ein Fehler auftritt, sollte der Parser in der Lage, damit umzugehen und weitermachen Parsen der Rest eingegeben werden. Meistens ist es erwartet aus dem Parser zu überprüfen auf Fehler kann jedoch zu Fehlern in den verschiedenen Stadien des Übersetzungsvorgangs auftreten. Ein Programm kann die folgenden Arten von Fehlern in den verschiedenen Phasen haben:
Lexikalische : Name von einige Bezeichner getippt falsch
Syntaktisch : fehlende Semikolon oder unsymmetrische Klammern
Semantische : unvereinbar Wert zuweisung
Logische : Code nicht erreichbar ist, Endlosschleife
Es gibt vier allgemeine Fehler behebungs strategien, die im Parser implementiert werden können, um mit Fehler im Code zu tun.
Panik-Modus
Wenn ein Parser Begegnungen einen Fehler irgendwo in der Erklärung, es ignoriert den Rest der Anweisung durch nicht verarbeitet Eingaben von Fehleingaben, um Trennzeichen, wie beispielsweise Strichpunkt. Dies ist der einfachste Weg, Fehlerbehebungs und auch verhindert, dass der Parser aus Entwicklungs Endlosschleifen.
Erklärung Modus
Wenn ein Parser einen Fehler feststellt, versucht es, Korrekturmaßnahmen zu ergreifen, so dass der Rest der Eingänge der Erklärung zu erlauben kann der Parser im Voraus analysieren. Zum Beispiel das Einfügen eines fehlenden Semikolon ersetzt Komma mit einem Semikolon usw. Parser Designer müssen vorsichtig sein, hier, weil eine falsche Korrektur kann zu einer Endlosschleife führen.
Fehler Produktionen
Einige häufige Fehler werden bekannt zu den Compiler-Designer, die im Code auftreten können. Darüber hinaus können die Designer Augmented Grammatik zu schaffen, um verwendet werden, da Produktionen, die fehlerhafte Konstrukte zu erzeugen, wenn diese Fehler auftreten.
Globale Korrektur
Der Parser hält das Programm in der Hand als Ganzes und versucht, herauszufinden, was das Programm soll zu tun und versucht, eine beste Übereinstimmung für sie, das fehlerfrei ist herauszufinden. Wenn eine fehlerhafte Eingabe (Anweisung) X zugeführt wird, erzeugt er eine Parserbaum irgendeinem engsten fehlerfreie Aussage Y. Dies kann es der Parser minimalen Änderungen im Quellcode zu machen, aber aufgrund der Komplexität (Zeit und Raum) des diese Strategie, die es in der Praxis nicht vorhanden umgesetzt.
abstrakt Syntax Bäume
Parse Baum Darstellungen sind nicht leicht, durch den Compiler analysiert werden, da sie mehr Details, als tatsächlich benötigt werden. Nehmen Sie das folgende Syntaxbaum als Beispiel:
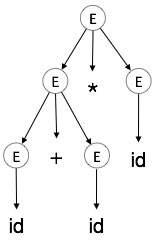
Wenn genau beobachtet, so finden wir die meisten der Blattknoten sind einzelne Kind zu ihren übergeordneten Knoten. Diese Informationen können vor der Zuführung in die nächste Phase eliminiert werden. Durch das Verbergen zusätzliche Informationen, können wir einen Baum zu erhalten, wie unten dargestellt:

Abstrakter Baum kann wie folgt dargestellt werden:

ASTs sind wichtige Datenstrukturen in einem Compiler mit mindestens unnötigen Informationen. ASTs sind kompakter als ein Parserbaum und kann leicht durch einen Kompilierer verwendet werden
