Beautiful Soup - Trouble Shooting
Error Handling
There are two main kinds of errors that need to be handled in BeautifulSoup. These two errors are not from your script but from the structure of the snippet because the BeautifulSoup API throws an error.
The two main errors are as follows −
AttributeError
It is caused when the dot notation doesn’t find a sibling tag to the current HTML tag. For example, you may have encountered this error, because of missing “anchor tag”, cost-key will throw an error as it traverses and requires an anchor tag.
KeyError
This error occurs if the required HTML tag attribute is missing. For example, if we don’t have data-pid attribute in a snippet, the pid key will throw key-error.
To avoid the above two listed errors when parsing a result, that result will be bypassed to make sure that a malformed snippet isn’t inserted into the databases −
except(AttributeError, KeyError) as er:
pass
diagnose()
Whenever we find any difficulty in understanding what BeautifulSoup does to our document or HTML, simply pass it to the diagnose() function. On passing document file to the diagnose() function, we can show how list of different parser handles the document.
Below is one example to demonstrate the use of diagnose() function −
from bs4.diagnose import diagnose
with open("20 Books.html",encoding="utf8") as fp:
data = fp.read()
diagnose(data)
Output
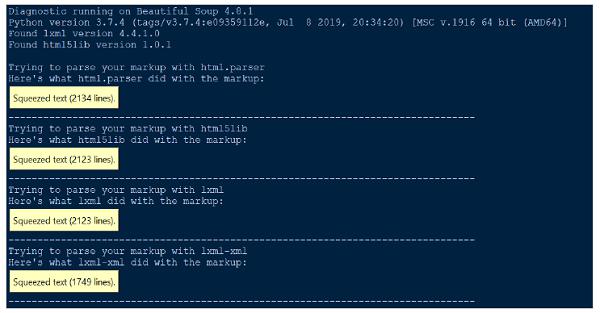
Parsing error
There are two main types of parsing errors. You might get an exception like HTMLParseError, when you feed your document to BeautifulSoup. You may also get an unexpected result, where the BeautifulSoup parse tree looks a lot different from the expected result from the parse document.
None of the parsing error is caused due to BeautifulSoup. It is because of external parser we use (html5lib, lxml) since BeautifulSoup doesn’t contain any parser code. One way to resolve above parsing error is to use another parser.
from HTMLParser import HTMLParser
try:
from HTMLParser import HTMLParseError
except ImportError, e:
# From python 3.5, HTMLParseError is removed. Since it can never be
# thrown in 3.5, we can just define our own class as a placeholder.
class HTMLParseError(Exception):
pass
Python built-in HTML parser causes two most common parse errors, HTMLParser.HTMLParserError: malformed start tag and HTMLParser.HTMLParserError: bad end tag and to resolve this, is to use another parser mainly: lxml or html5lib.
Another common type of unexpected behavior is that you can’t find a tag that you know is in the document. However, when you run the find_all() returns [] or find() returns None.
This may be due to python built-in HTML parser sometimes skips tags it doesn’t understand.
XML parser Error
By default, BeautifulSoup package parses the documents as HTML, however, it is very easy-to-use and handle ill-formed XML in a very elegant manner using beautifulsoup4.
To parse the document as XML, you need to have lxml parser and you just need to pass the “xml” as the second argument to the Beautifulsoup constructor −
soup = BeautifulSoup(markup, "lxml-xml")
or
soup = BeautifulSoup(markup, "xml")
One common XML parsing error is −
AttributeError: 'NoneType' object has no attribute 'attrib'
This might happen in case, some element is missing or not defined while using find() or findall() function.
Other parsing errors
Given below are some of the other parsing errors we are going to discuss in this section −
Environmental issue
Apart from the above mentioned parsing errors, you may encounter other parsing issues such as environmental issues where your script might work in one operating system but not in another operating system or may work in one virtual environment but not in another virtual environment or may not work outside the virtual environment. All these issues may be because the two environments have different parser libraries available.
It is recommended to know or check your default parser in your current working environment. You can check the current default parser available for the current working environment or else pass explicitly the required parser library as second arguments to the BeautifulSoup constructor.
Case-insensitive
As the HTML tags and attributes are case-insensitive, all three HTML parsers convert tag and attribute names to lowercase. However, if you want to preserve mixed-case or uppercase tags and attributes, then it is better to parse the document as XML.
UnicodeEncodeError
Let us look into below code segment −
soup = BeautifulSoup(response, "html.parser")
print (soup)
Output
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'
Above problem may be because of two main situations. You might be trying to print out a unicode character that your console doesn’t know how to display. Second, you are trying to write to a file and you pass in a Unicode character that’s not supported by your default encoding.
One way to resolve above problem is to encode the response text/character before making the soup to get the desired result, as follows −
responseTxt = response.text.encode('UTF-8')
KeyError: [attr]
It is caused by accessing tag[‘attr’] when the tag in question doesn’t define the attr attribute. Most common errors are: “KeyError: ‘href’” and “KeyError: ‘class’”. Use tag.get(‘attr’) if you are not sure attr is defined.
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "howcodex" in item['href']):
(...)
except KeyError:
pass # or some other fallback action
AttributeError
You may encounter AttributeError as follows −
AttributeError: 'list' object has no attribute 'find_all'
The above error mainly occurs because you expected find_all() return a single tag or string. However, soup.find_all returns a python list of elements.
All you need to do is to iterate through the list and catch data from those elements.
